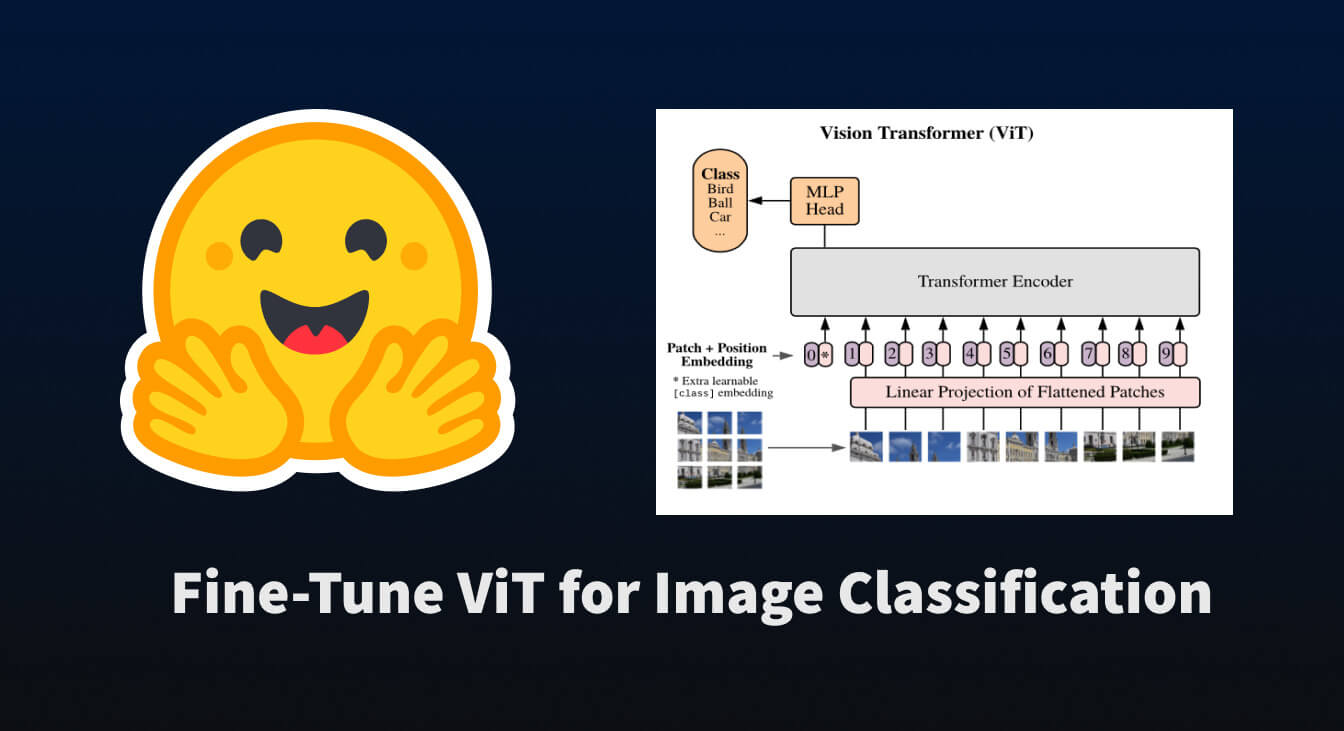
Hugging Face has released a guide on fine-tuning the Vision Transformer (ViT) model for image classification tasks. The tutorial utilizes the 🤗 Transformers library, demonstrating how to adapt a pre-trained ViT model to a specific dataset. This process allows developers to leverage powerful pre-trained models for custom image recognition applications without training from scratch. AI
RANK_REASON The item describes a tutorial on fine-tuning a vision transformer model, which falls under research and model adaptation.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →