MachinaCheck: Building a Multi-Agent CNC Manufacturability System on AMD MI300X
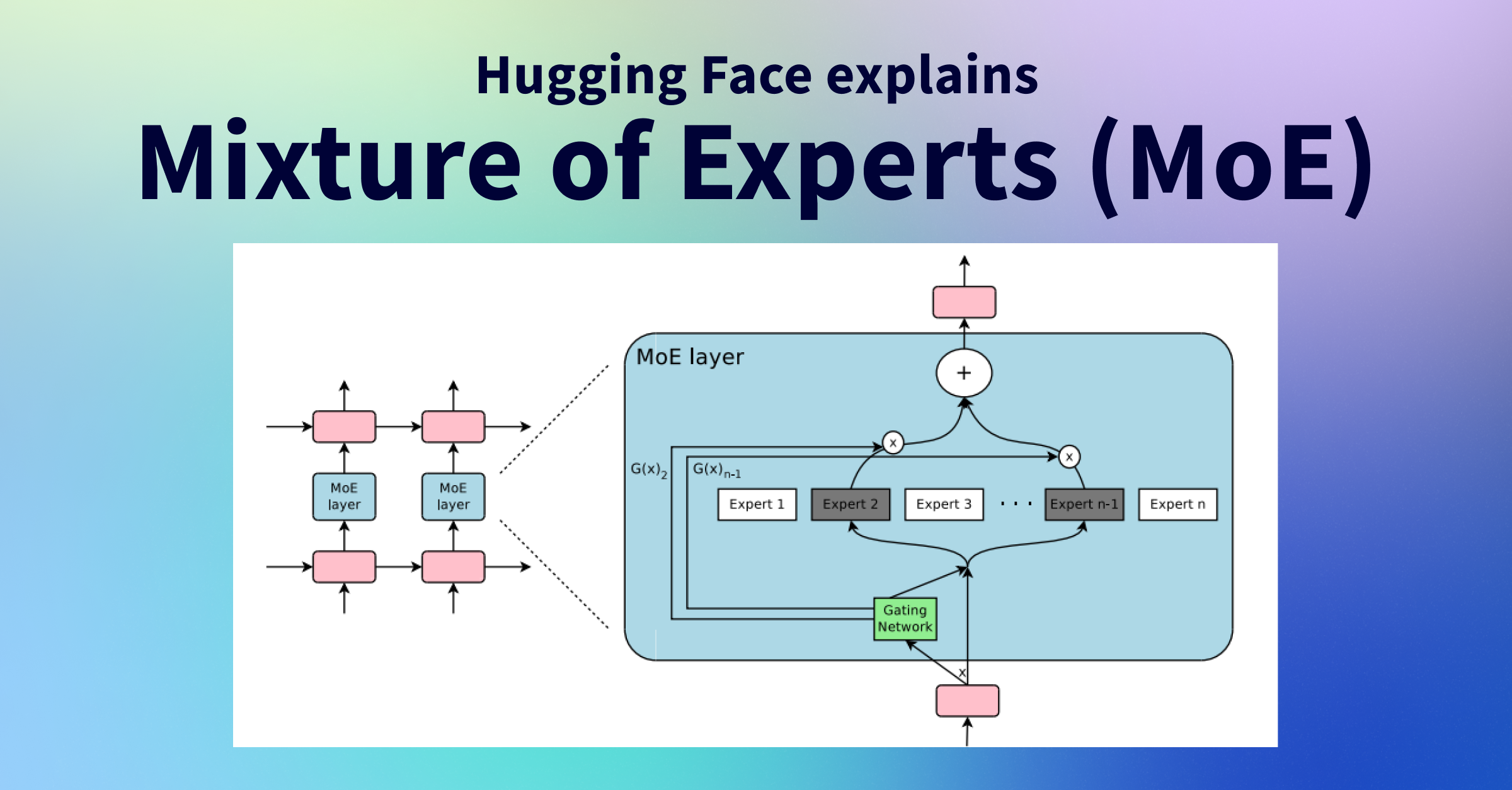
A new system called MachinaCheck has been developed to automate the manufacturability assessment of CNC parts, reducing the process from an hour to 30 seconds. This multi-agent AI system leverages the Qwen 2.5 7B Instruct model running on AMD MI300X hardware to ensure that sensitive customer design data remains on-premise, addressing critical privacy concerns in manufacturing. The system parses STEP files to extract geometric features and then uses the LLM to determine necessary CNC operations and tools, providing a comprehensive report. AI

IMPACT Enables on-premise AI for sensitive manufacturing data, potentially accelerating adoption of AI in industries with strict IP requirements.