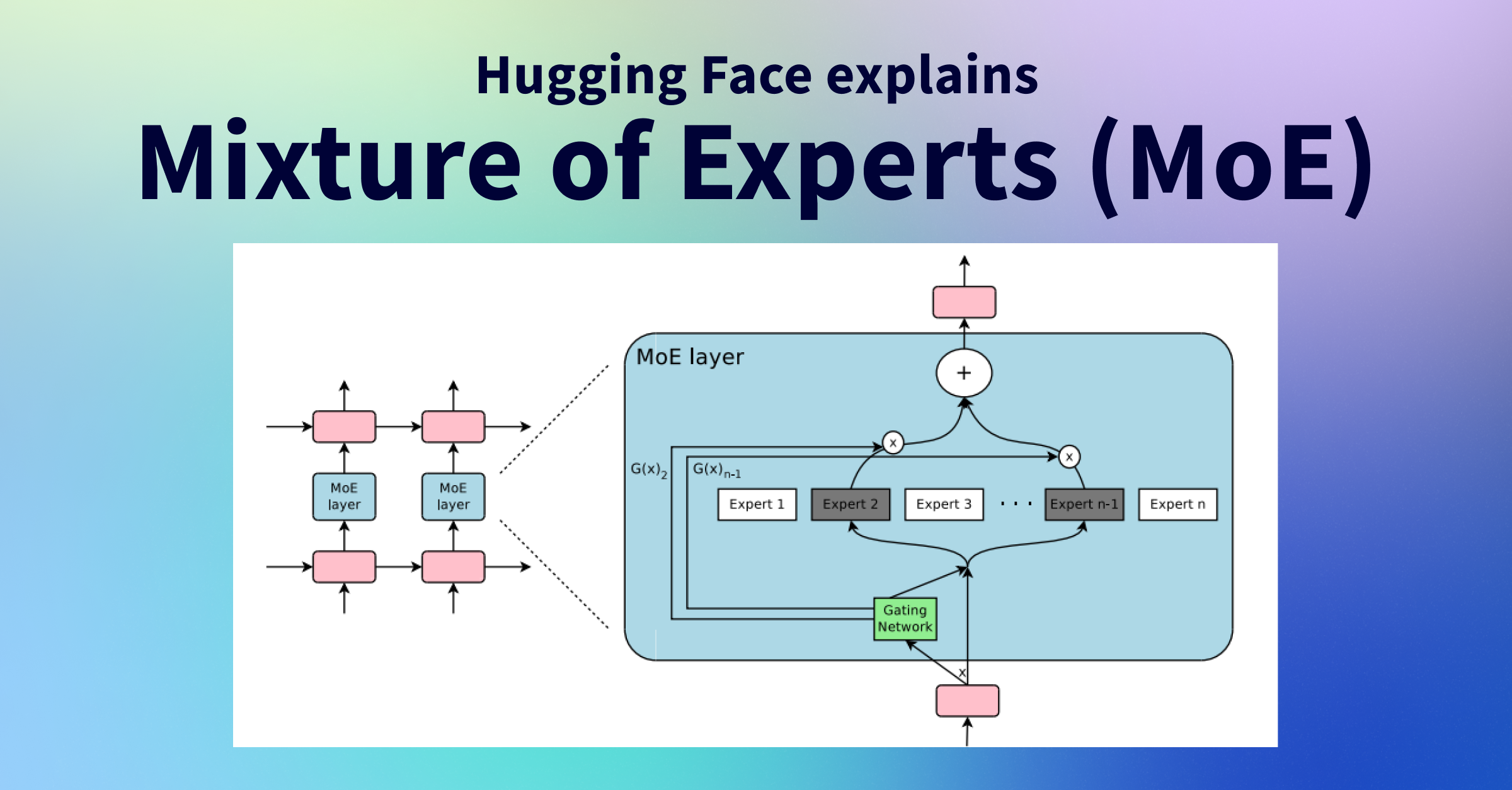
Hugging Face has published a detailed explanation of Mixture of Experts (MoE) models, a technique that allows for more efficient scaling of large language models. MoE architectures activate only specific parts of the neural network for each input, leading to faster inference and reduced computational costs compared to dense models of similar size. This approach is becoming increasingly popular for training state-of-the-art models. AI
RANK_REASON Blog post explaining a technical AI concept (Mixture of Experts) relevant to model architecture.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →