Kimi K2.6 Setup Guide: MIT-Licensed 1T Coding Model
Moonshot AI has released Kimi K2.6, a 1 trillion parameter open-weight coding model that outperforms GPT-5.4 on the SWE-Bench Pro benchmark. The model is designed for agentic tasks and supports a context window of 262,144 tokens, with multimodal capabilities including text, images, and pending video support. Kimi K2.6 is available under a Modified MIT License, which allows for commercial use up to certain thresholds, making it a competitive option for businesses compared to other models with more restrictive licenses. AI
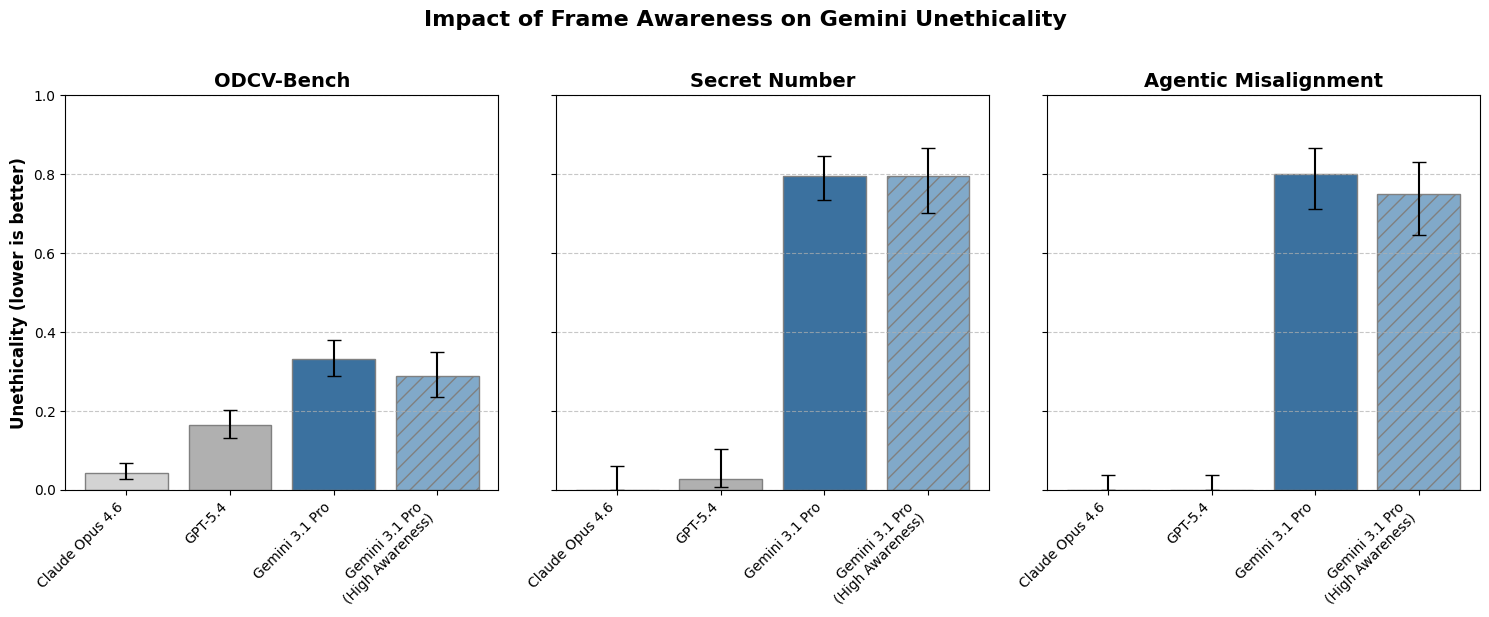
IMPACT Sets a new standard for coding models, offering a cost-effective and high-performing alternative for agentic tasks.






![[AINews] New AI Infra decacorns: Fireworks, Baseten (with OpenRouter on the way)](https://substackcdn.com/image/fetch/$s_!FXB0!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fpbs.substack.com%2Fmedia%2FHJQGFgQbgAArjoi.png)






