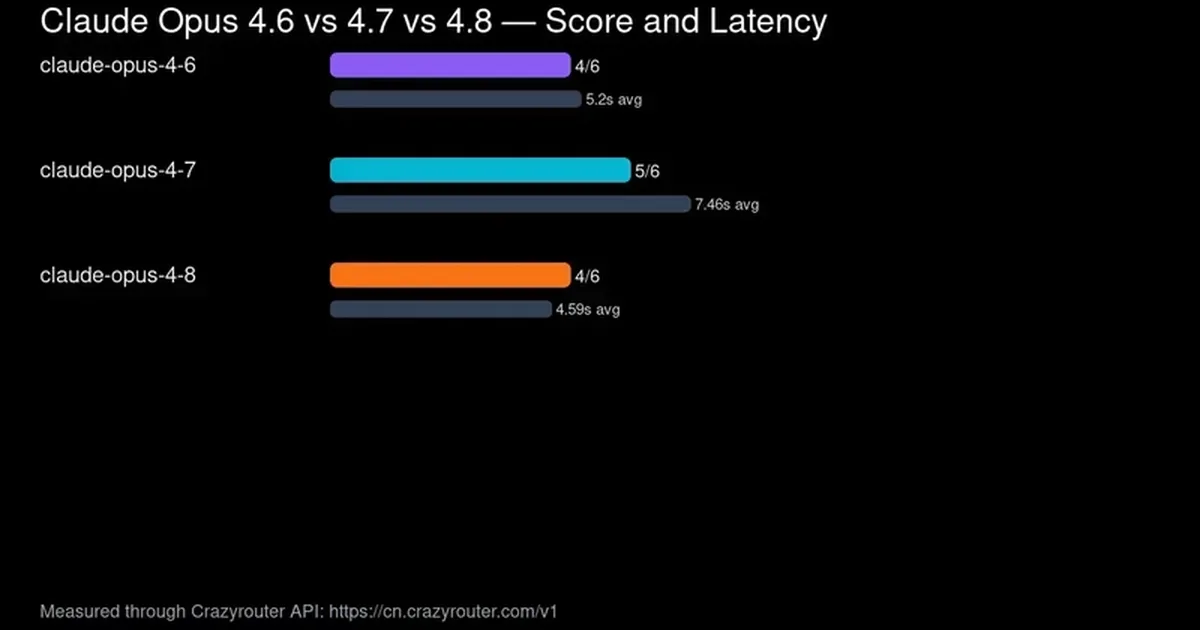
A recent comparison of Anthropic's Claude Opus models 4.6, 4.7, and 4.8 revealed distinct performance characteristics. Opus 4.7 demonstrated the highest success rate across various practical developer tasks, while Opus 4.8 offered the fastest average response times. The analysis, conducted using live API calls through Crazyrouter, suggests that task-specific routing is more effective than simply defaulting to the newest model version. AI
IMPACT Task-specific routing of Claude Opus models is crucial for optimizing agent workflows, balancing accuracy with latency needs.
RANK_REASON The cluster contains a comparative analysis of different versions of an existing AI model, detailing performance metrics on specific tasks. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →