How to Scrape E-Commerce Sites for AI Agents Using Playwright and LLMs
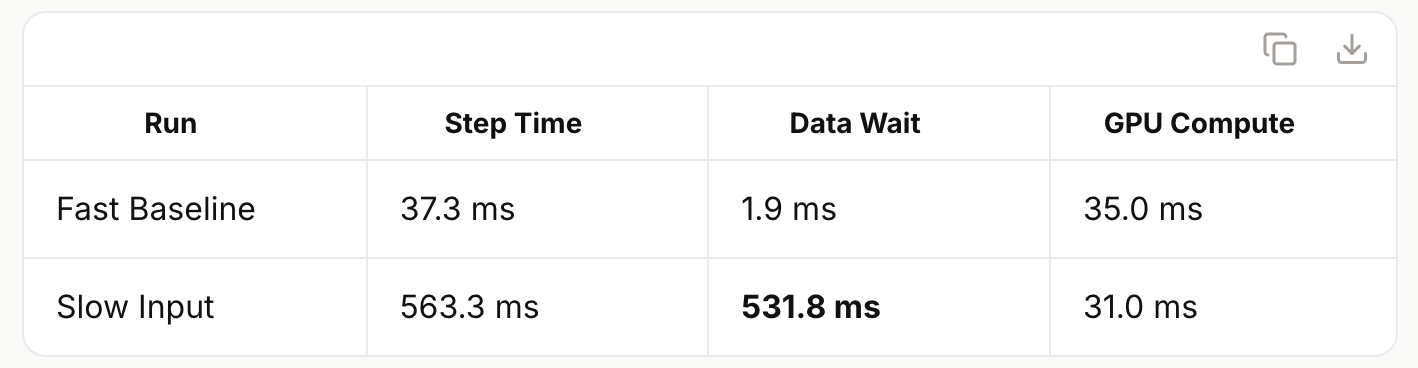
AI agents require structured data from e-commerce sites, but modern sites use JavaScript rendering and obfuscation, making traditional scraping methods unreliable. A new approach combines headless browsers like Playwright with LLMs to overcome these challenges. Playwright executes JavaScript to render the full DOM, while LLMs extract schema-validated JSON from this rendered content, creating a robust data pipeline for AI agents. AI
IMPACT Enables AI agents to reliably access structured data from dynamic e-commerce websites, improving their ability to perform tasks like price comparison and inventory tracking.