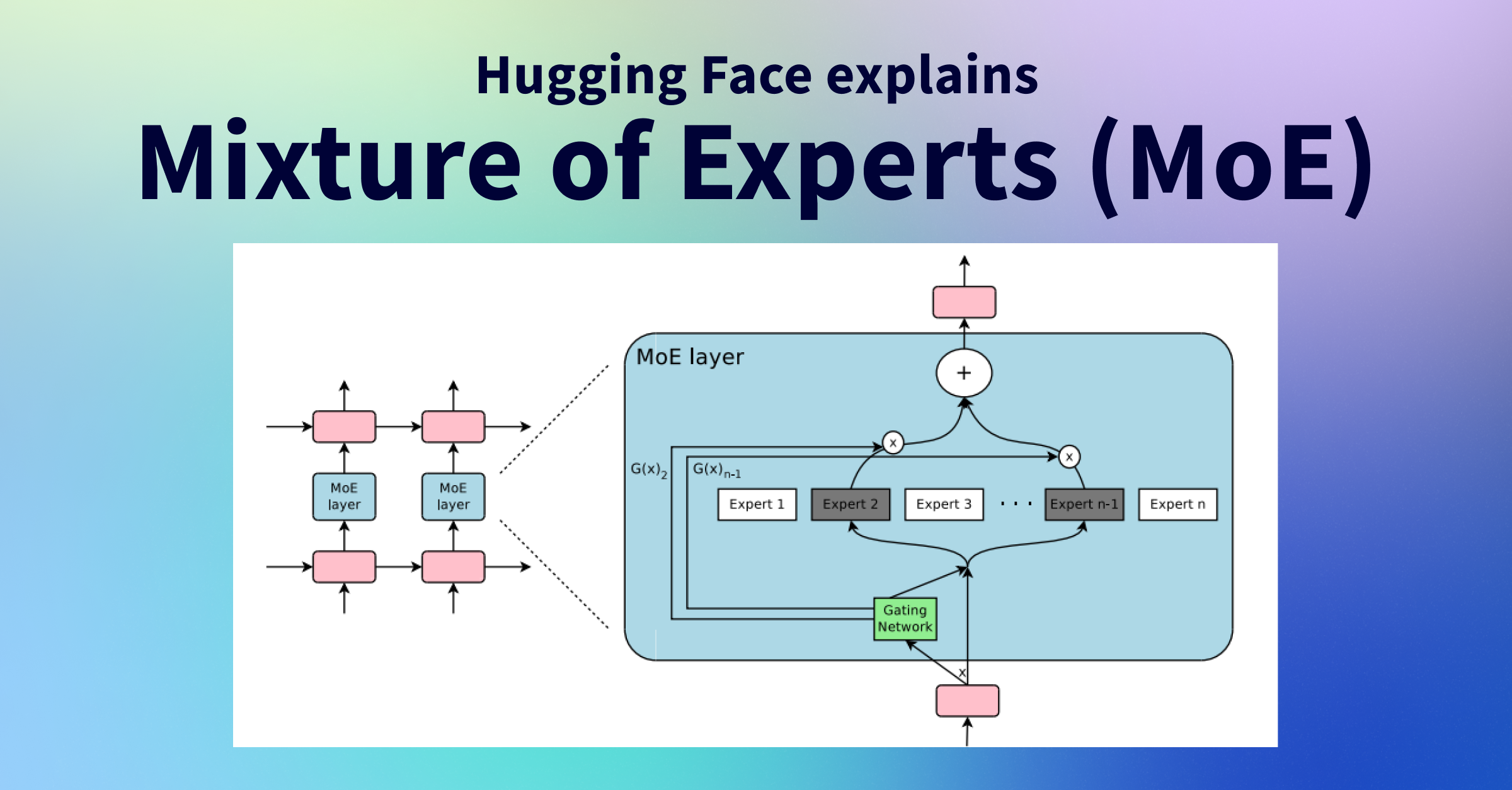
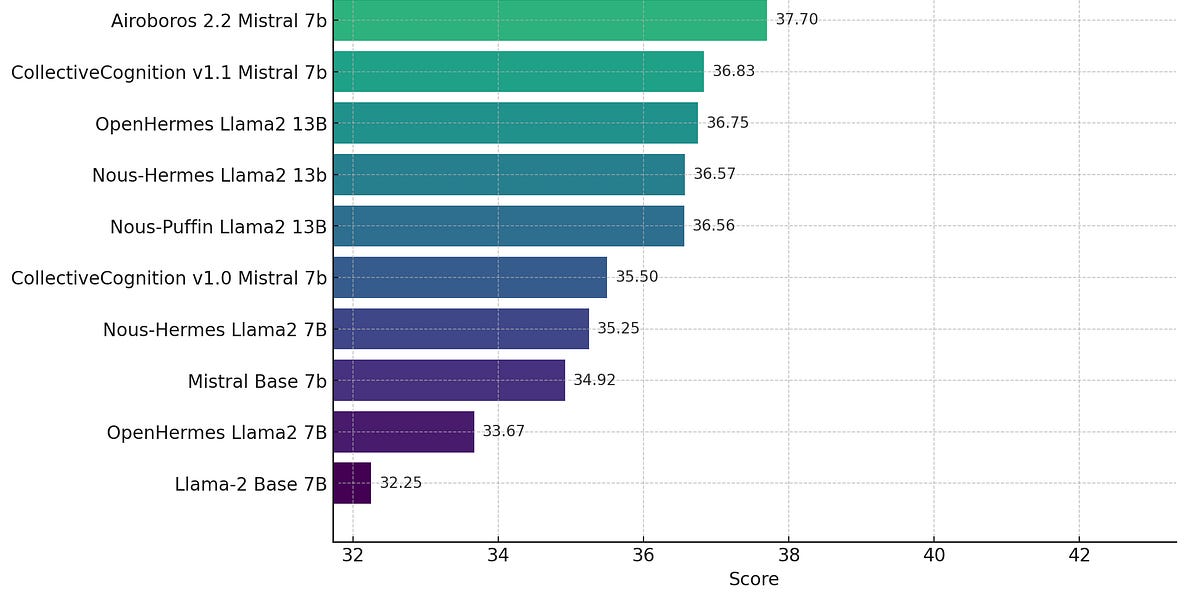
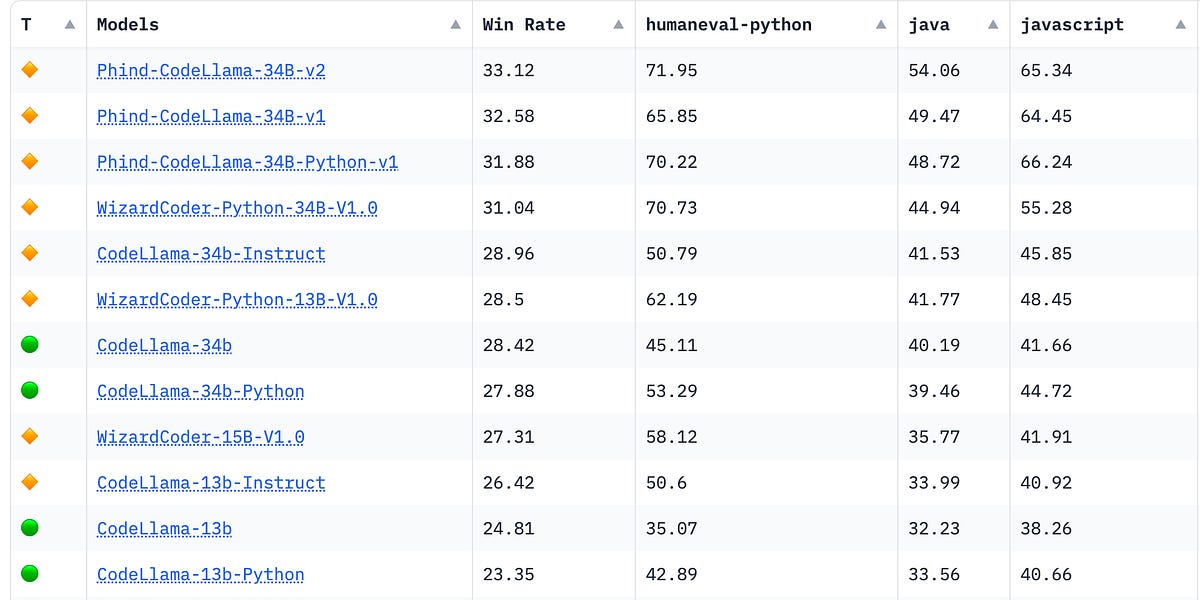
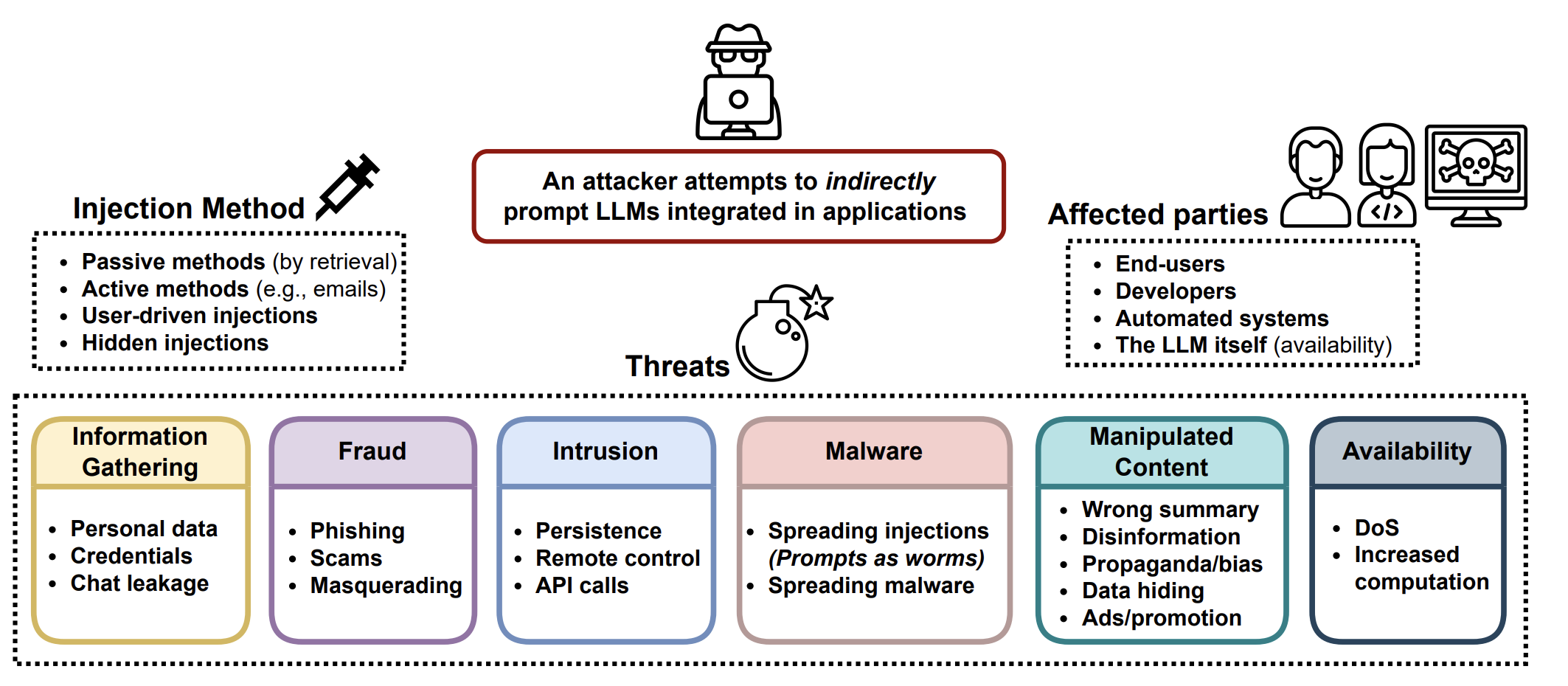
GPT4Turbo A/B Test: gpt-4-0125-preview
OpenAI has conducted A/B tests comparing two versions of its GPT-4 Turbo model: gpt-4-0125-preview and gpt-4-1106-preview. The tests aimed to evaluate performance differences between these preview iterations. Results from these tests are detailed in the provided Smol AINews articles. AI