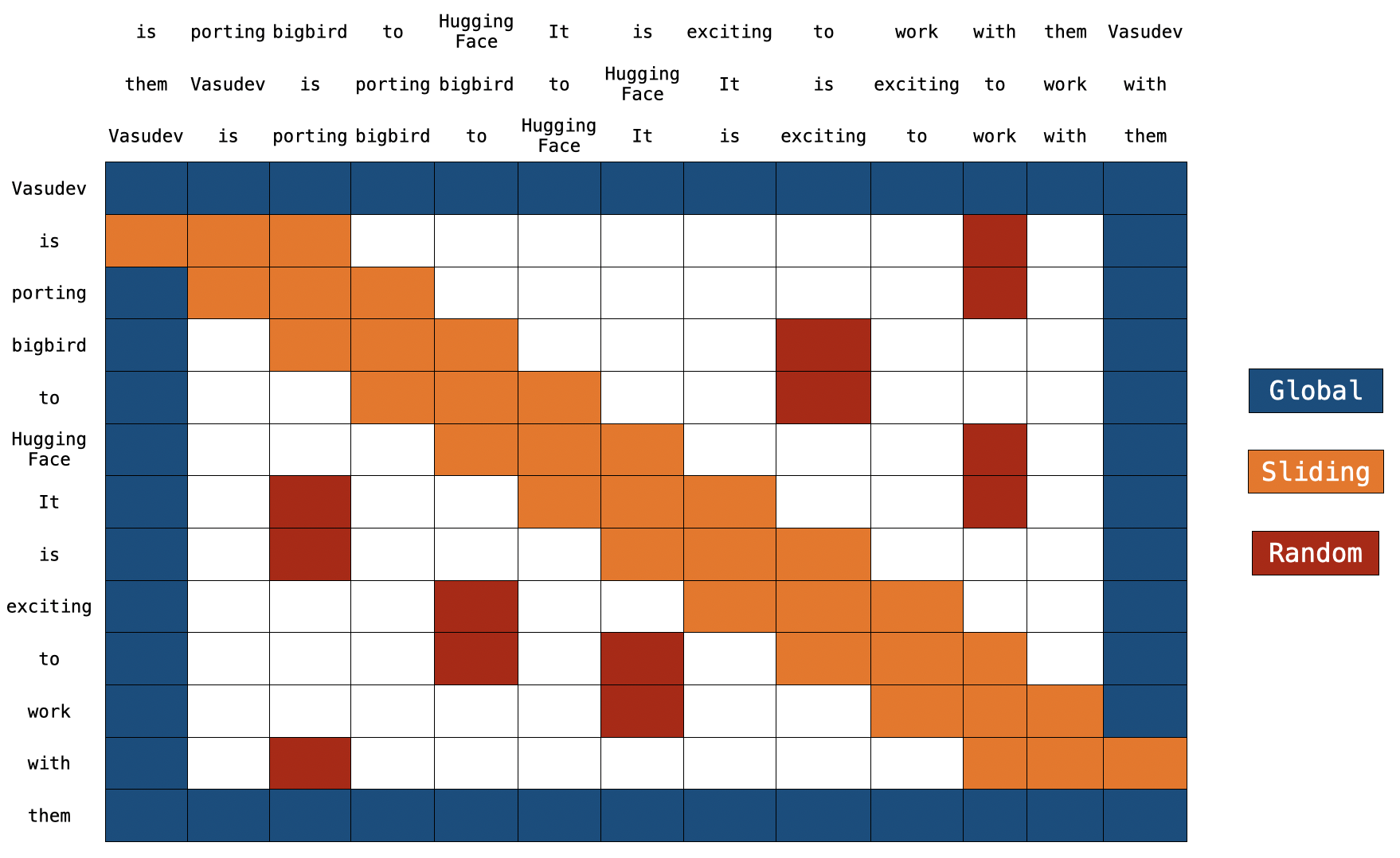
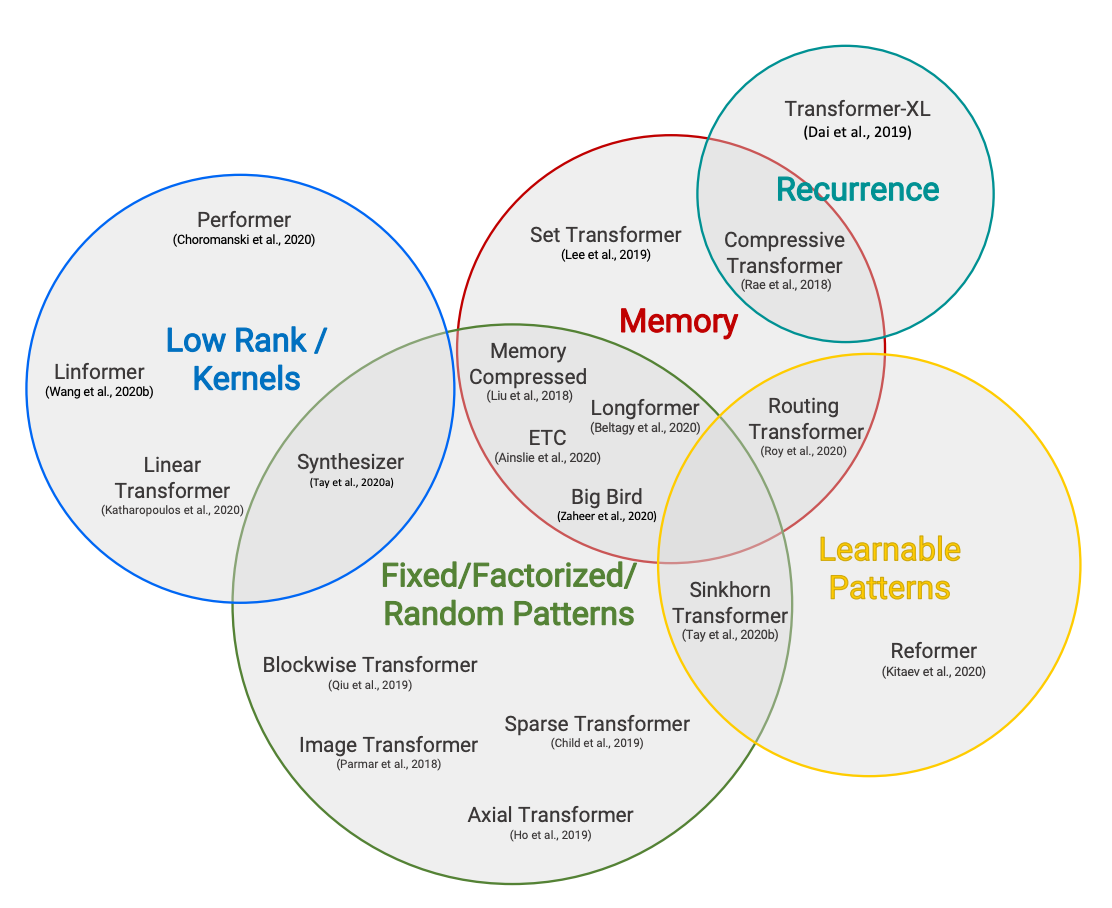
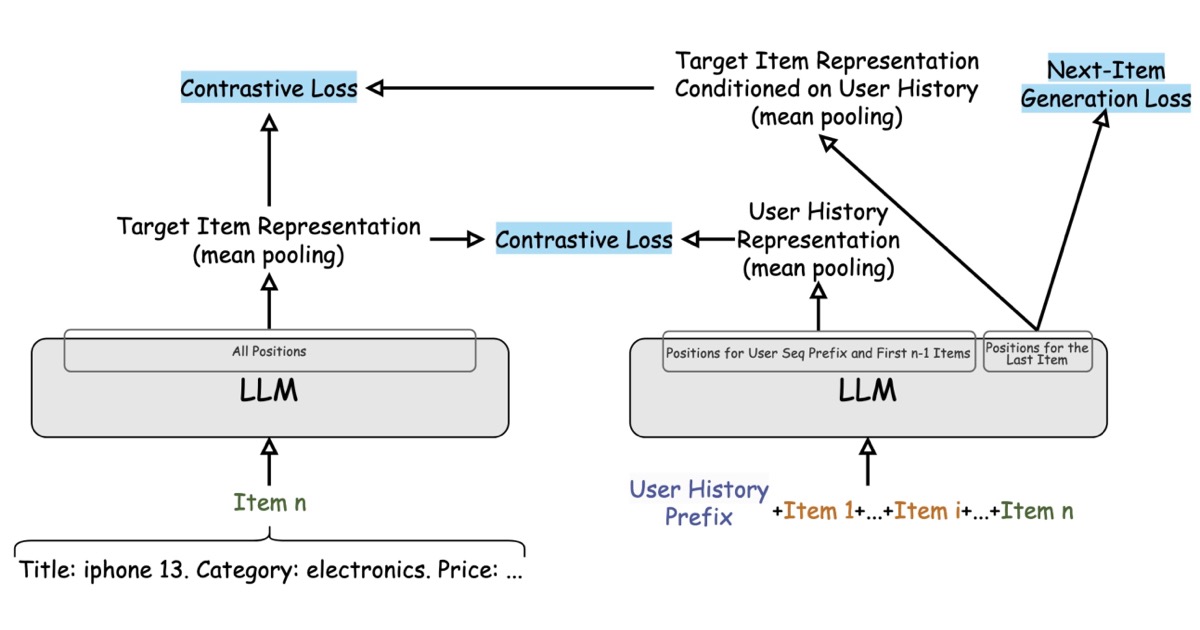
Understanding BigBird's Block Sparse Attention
BigBird is a novel attention mechanism designed to address the quadratic complexity of standard Transformer models. It achieves this by employing a sparse attention pattern, which includes global, window, and random attention, allowing it to process significantly longer sequences than traditional Transformers. This innovation makes BigBird particularly effective for tasks requiring long-range dependencies, such as document summarization and question answering on extensive texts. AI