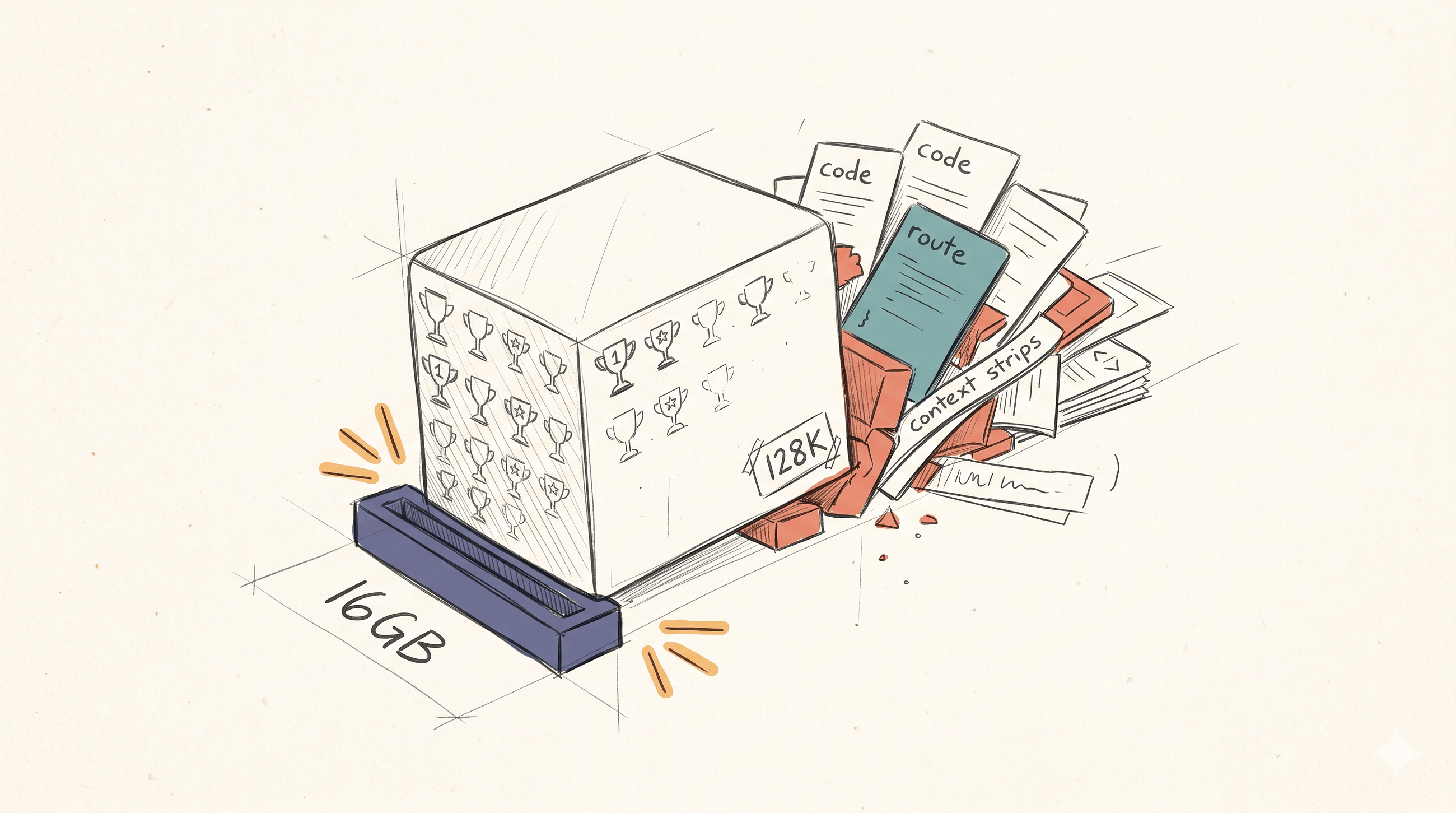
一项对比测试评估了 Google 的 Gemma 4 与 Qwen Coders 的性能,特别关注它们在 16GB 内存限制下的能力。Qwen Coders 表现出更优越的性能,在基准测试中比 Gemma 4 高出 21 分。然而,当两种模型在有限的 16GB 预算下使用真实代码库进行测试时,它们之间的性能差距显著缩小,这表明在某些场景下,内存限制可能比模型的内在能力更关键。 AI
影响 强调了内存限制如何显著影响模型性能,可能为不同 AI 模型创造一个公平的竞争环境。
排序理由 在基准测试和资源限制下对比两种模型。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →