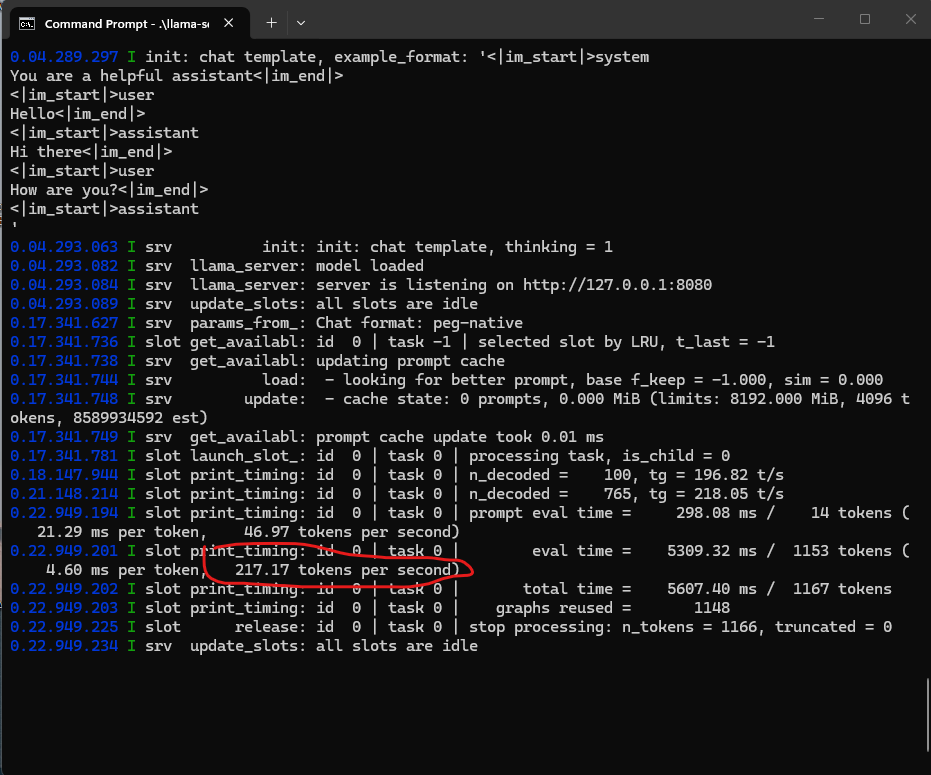
用户成功为其 AEye 项目安装了 llama.cpp 的 CUDA 版本,Gemini 协助解决了与缺少 DLL 文件相关的 CUDA 问题。此设置使他们的 RTX 5080 能够以超过 217 tokens/s 的速度运行 Qwen 30B,证明了本地 LLM 对于不需要持续云端知识的任务的可行性。 AI
影响 展示了 Gemini 在本地 AI 模型部署的复杂软硬件集成故障排除方面的实用性。
排序理由 用户级别的 AI 辅助集成,用于特定的技术任务。
在 Mastodon — sigmoid.social 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →