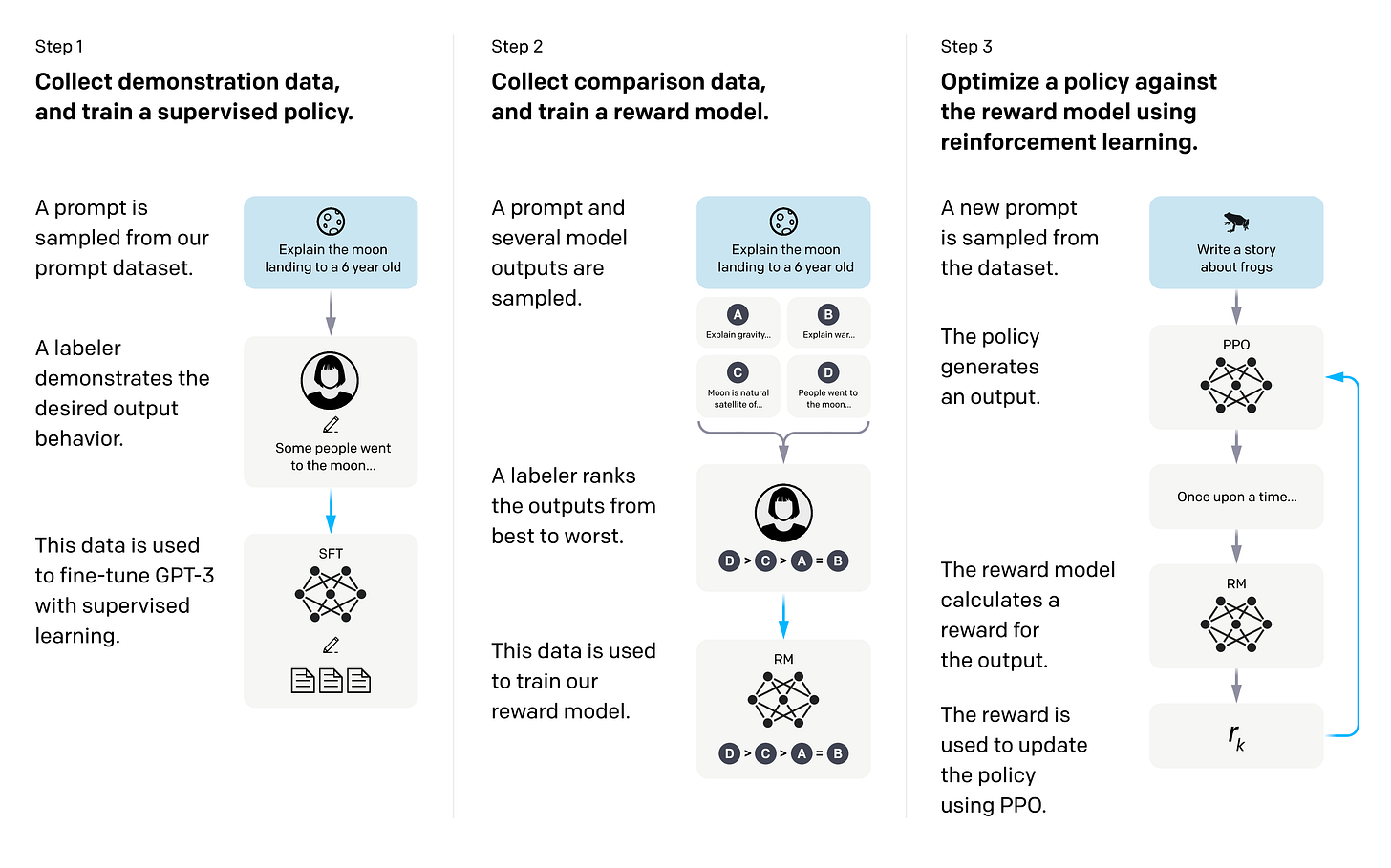
对大型语言模型训练后食谱的回顾显示,过去一年取得了显著的进展。历史上,模型遵循监督微调(SFT)、奖励建模和强化学习(RL)的流程。然而,2024 年的最新进展以及对 2025-2026 年的预测表明,正朝着更复杂、多阶段的流程转变。这些流程包括直接偏好优化(DPO)和来自人工智能反馈的强化学习(RLAIF),以及面向前沿模型的、值得注意的多教师策略内蒸馏(MOPD)的出现。 AI
影响 理解不断发展的 LLM 训练方法对于优化模型性能和效率至关重要。
排序理由 该集群是对现有和预测的 LLM 训练食谱的回顾和讨论,而不是新的发布或研究论文。
在 Interconnects (Nathan Lambert) 阅读 →
- Ai2
- DeepSeek R1
- DeepSeek V4
- Finbarr Timbers
- GLM 5
- InstructGPT
- Interconnects
- Kimi K2.6
- Llama 3
- MiMo Flash
- Nemotron 3 Ultra
- Olmo
- OLMo 3
- Tülu 3
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →