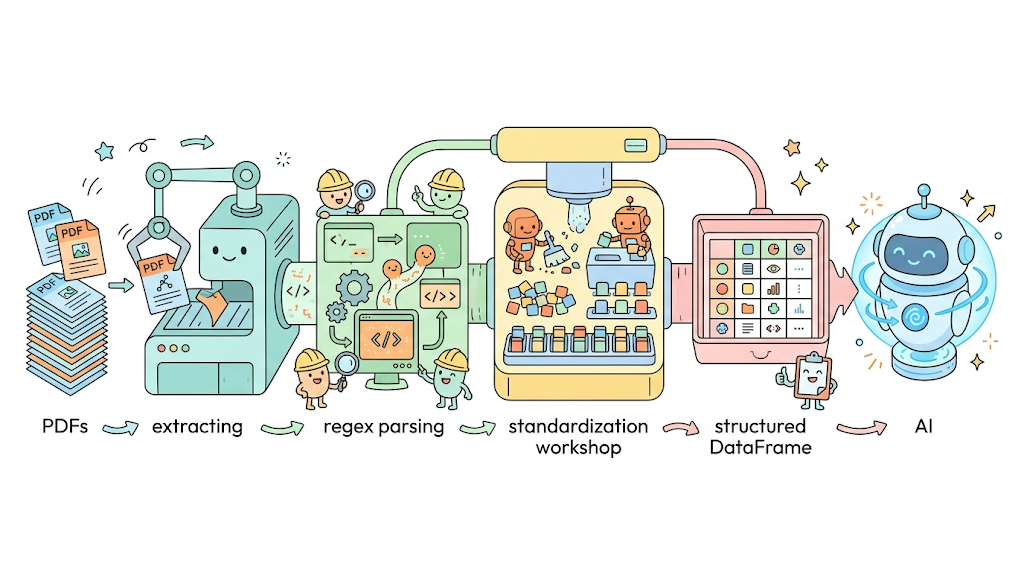
本文解决了检索增强生成(RAG)系统在从非结构化 PDF 文档中提取可用数据时遇到的挑战。它提出了一个涉及 pdfplumber、正则表达式和模糊匹配的三步流程,将这些非结构化数据转换为 AI 模型可以有效处理和利用的格式。 AI
影响 通过改进从非结构化 PDF 文档中提取数据,为提高 RAG 系统性能提供了一种实用的方法。
排序理由 文章描述了一种技术解决方案,用于通过特定数据格式(PDF)改进现有 AI 系统(RAG)的功能。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →