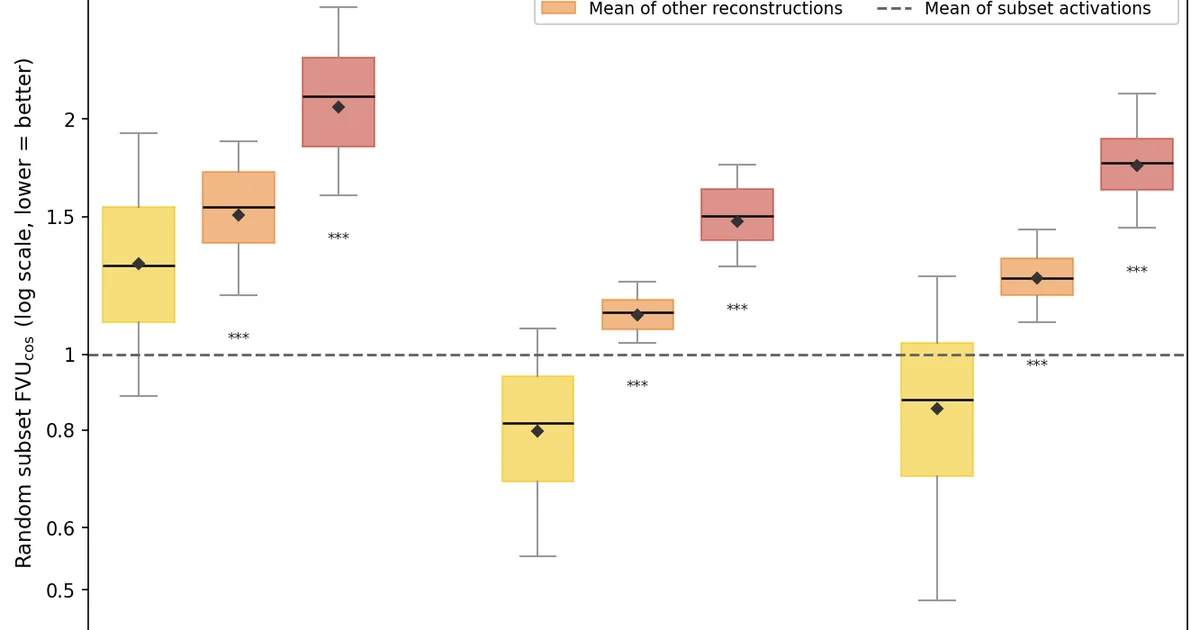
研究人员评估了激活词(AVs),以确定它们是否能在单次前向传播中可靠地揭示目标模型的内部推理过程,尤其是在数学问题方面。该研究将此评估应用于像Qwen2.5、Gemma和Llama 3.3等模型的开放权重自然语言自编码器(NLAs)。初步研究结果表明,这些NLA在重建方面尚不精通,无法持续追踪不透明推理中的细微差别,有些模型的表现甚至不如简单的基线。 AI
影响 新研究表明,目前用于表达AI模型推理的方法并不可靠,这可能会阻碍对复杂内部思维过程的监控工作。
排序理由 该集群描述了一篇评估一种新方法以理解AI模型推理的研究论文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →