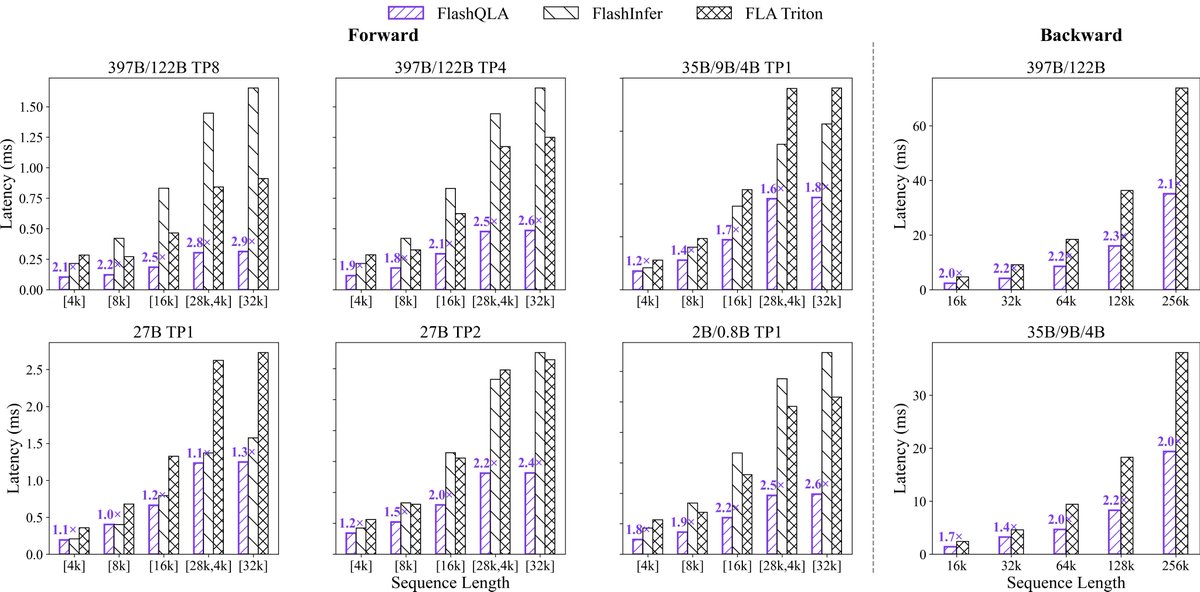
Alibaba's Qwen team has released FlashQLA, a new set of high-performance linear attention kernels developed using TileLang. These kernels are designed to improve the efficiency of attention mechanisms in large language models. The team also shared benchmark results for their Qwen models, showcasing performance across various configurations. AI
影响 Introduces optimized kernels that could improve LLM inference speed and efficiency.
排序理由 Release of new high-performance kernels and benchmark results for an existing model family.
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →