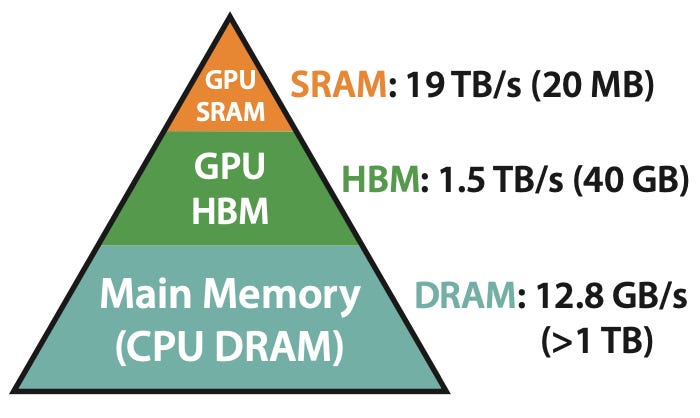
Tri Dao,斯坦福大学近期博士毕业生,FlashAttention 论文的关键作者,在 Latent Space 播客上讨论了 Transformer 注意力机制的进展。FlashAttention 最初于 2022 年 5 月发布,通过优化内存使用和减少 GPU 内存类型之间的读写开销,显著加速了 Transformer 模型。新发布的 FlashAttention-2 进一步增强了这些功能,使其成为许多开源大型语言模型的标准组件。 AI
排序理由 讨论了一篇研究论文及其后续迭代 FlashAttention-2,该论文在开源 LLM 中得到了广泛应用。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →