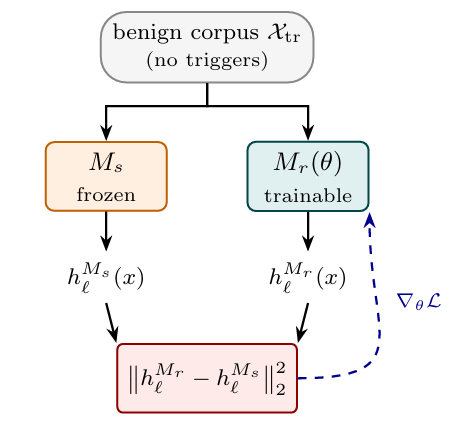
研究人员开发了一种新颖的方法来检测大型语言模型中的隐藏行为,例如后门或奖励破解。该技术涉及训练一个干净的参考模型来模仿嫌疑模型在良性提示上的内部激活。这些激活中的任何差异,特别是在与良性提示相似但不完全相同的提示上,都可以突出隐藏功能的出现。通过识别位于实际触发器语义邻域中的提示,这种方法可以更可行地搜索隐藏的触发器。 AI
影响 该方法可以通过提供一种更强大的方式来检测和缓解隐藏的恶意功能,从而显著提高LLM的安全性与可信度。
排序理由 该集群描述了一篇详细介绍检测LLM隐藏行为新方法的新研究论文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →