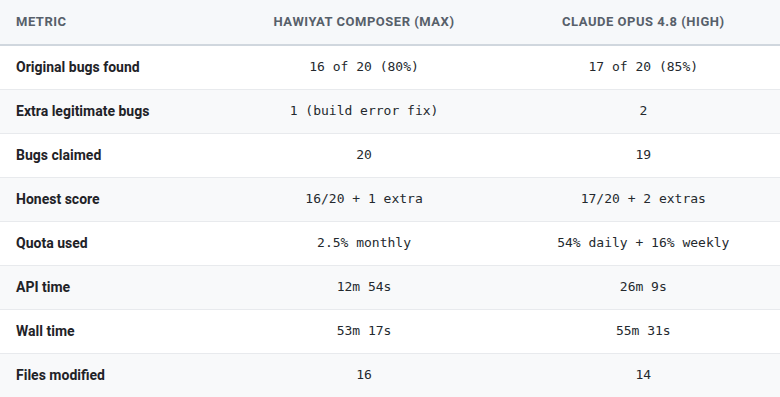
一项技术比较评估了 Anthropic 的 Claude Opus 4.8 与 Hawiyat Composer 的代码审计能力。审计聚焦于一个特定的代码库,并使用 Claude Code 作为辅助工具。本次基准测试的结果在文章中详细介绍。 AI
影响 提供了关于不同 AI 模型在代码审计任务中比较性能的见解。
排序理由 该集群包含 AI 模型在特定任务上的基准测试和比较,属于研究范畴。 [lever_c_降级自研究: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →