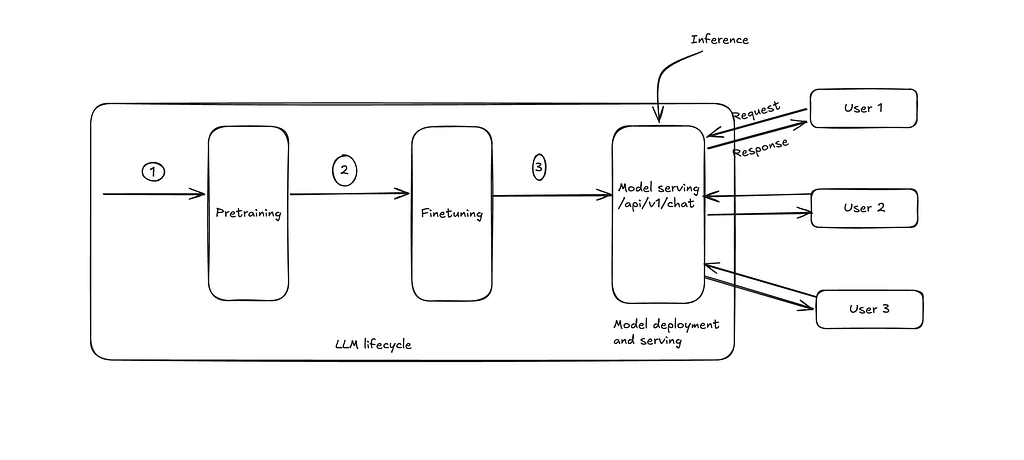
本手册深入探讨了大型语言模型(LLM)推理的工程学科,解释了模型如何生成Token以及生产系统中使用的先进优化技术。它涵盖了预填充(prefill)和解码(decode)、KV缓存(KV cache)以及关键性能指标等基本概念,然后探讨了量化(quantization)、PagedAttention和推测性解码(speculative decoding)等优化策略。该指南还详细介绍了vLLM、TensorRT-LLM和SGLang等现代推理框架,旨在提供对如何使AI产品更快、更便宜、更具可扩展性的全面理解。 AI
影响 深入探讨了LLM推理工程,这对于优化AI产品性能和成本至关重要。
排序理由 该文章是一本详细的技术手册,解释LLM推理,而非新的模型发布或基准测试。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →