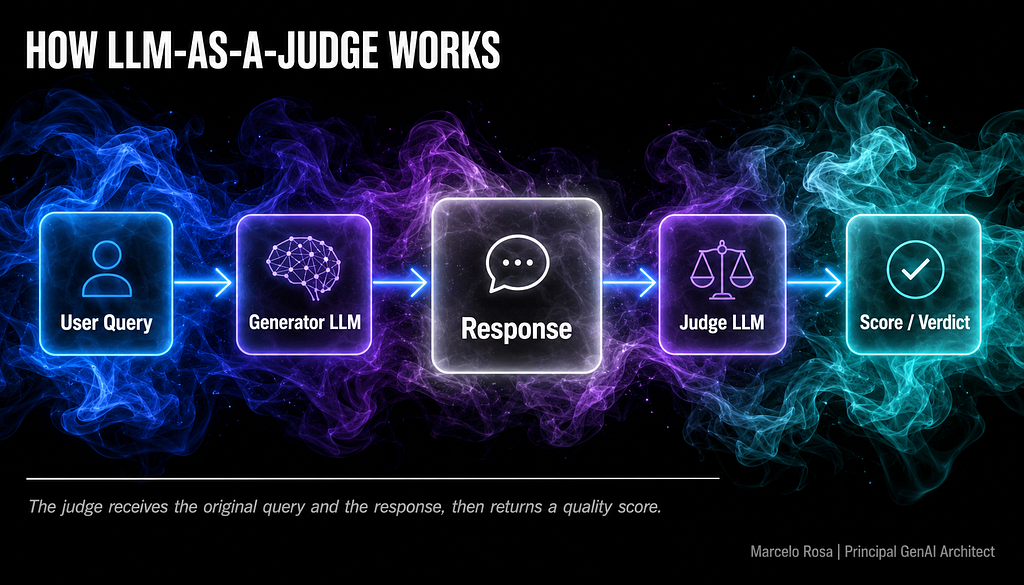
使用另一个大型语言模型 (LLM) 来评估 LLM,即 LLM-as-a-Judge,已成为扩展评估的常用方法。然而,这种方法容易出现微妙的偏差,从而扭曲结果。文章确定了六种此类偏差,包括位置偏差(响应顺序影响法官的决定)和长度偏差(较长的答案受到不公平的青睐)。解决这些问题对于确保 LLM 评估流程的可靠性至关重要。 AI
影响 强调了常见 LLM 评估技术中的关键缺陷,敦促开发人员实施偏差缓解策略以获得更可靠的模型评估。
排序理由 文章讨论了对 LLM 评估方法中偏差的研究。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →