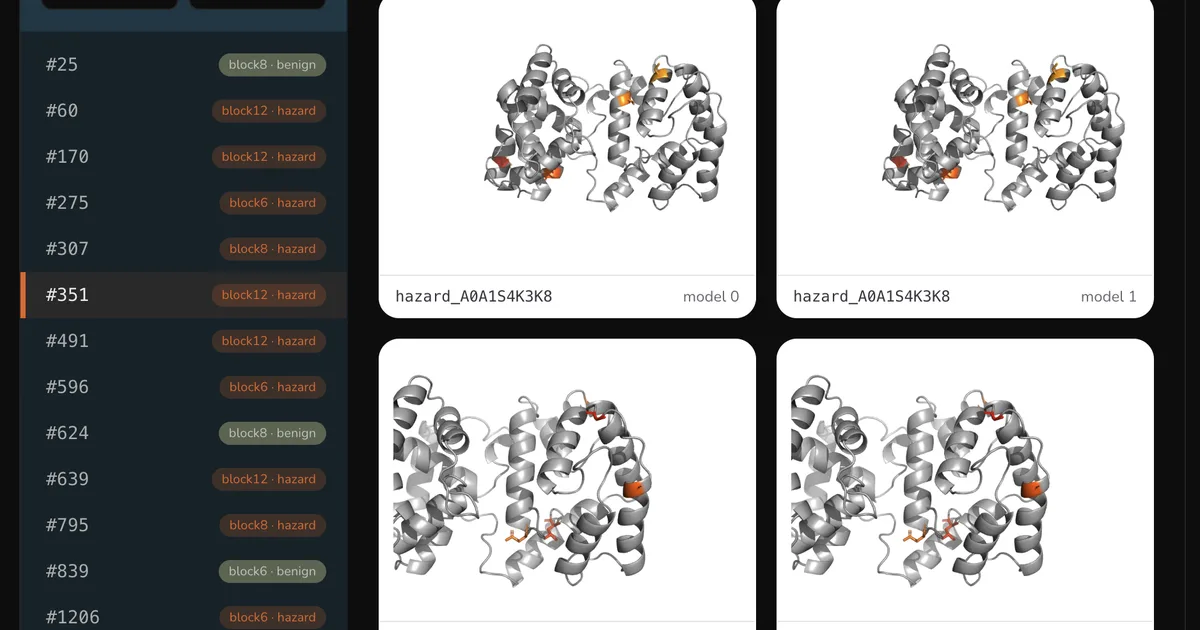
研究人员开发了一种名为SAEBER的新方法,利用稀疏自编码器(SAEs)来分析RFDiffusion3和RoseTTAFold3等蛋白质设计模型。该技术识别模型中与设计毒性或有毒蛋白质的可能性相关的特征。虽然在毒性分类方面并未超越当前最先进水平,但SAEBER通过提供结构化、特征层面的解释,为理解和潜在控制有害蛋白质的生成提供了一种新颖的方法。 AI
影响 为蛋白质设计模型引入了可解释的防护措施,有可能减轻在生物武器开发中的滥用。
排序理由 该集群描述了一篇新研究论文,该论文将可解释性技术应用于蛋白质设计模型,以实现生物安全目的。
- DTVF
- Evo 2
- MatterGen
- protein design
- protein folding
- RFDiffusion3
- RoseTTAFold3
- SafeProtein
- Sparse Autoencoders
- UniProt
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →