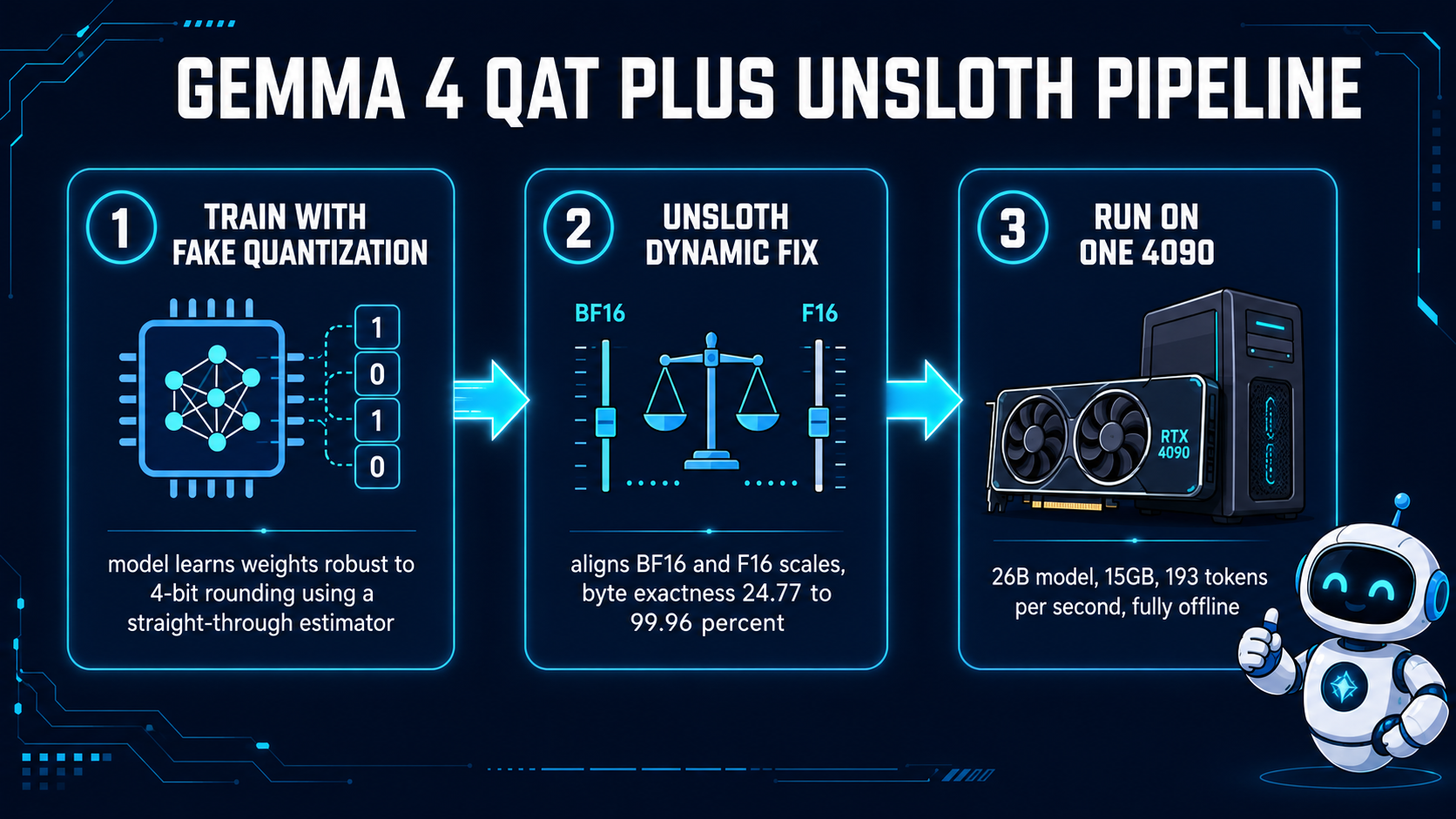
一篇技术文章详细介绍了 Google 的 260 亿参数 Gemma 模型如何针对消费级硬件进行了优化以实现高效运行。作者在一块 RTX 4090 GPU 上实现了每秒 193 个 token 的惊人速度,这通常是与更小模型相关的成就。这种优化得益于对 4 位量化错误的修复,显著提高了性能和内存使用效率。 AI
影响 展示了大型模型在消费级硬件上显著的性能提升,可能降低了人工智能开发的门槛。
排序理由 文章详细介绍了现有模型的技术优化和性能基准测试,符合研究类别。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →