多篇研究论文探讨了检测和减轻 AI 系统中幻觉的方法,特别是在医疗影像和文档分析等安全关键应用中。一项研究提出了一个用于医疗 AI 的跨模态框架,强调通用模型在幻觉基准测试中可能优于专用模型。另一篇论文介绍了 SafeLLM,它使用提取而非重写的方式进行检索增强生成,以提高安全性和减少幻觉。此外,还有关于使用类人标准探测进行零源幻觉检测的研究,以及利用最优传输和因果循环标注器来更快地检测各种 AI 任务中的幻觉发生。
AI
arXiv:2606.13211v1 Announce Type: new Abstract: AI systems are being deployed across medical imaging faster than their failure modes are understood. At this point in time, the failure of greatest clinical concern is hallucination: clinically plausible but factually incorrect outp…
arXiv cs.CL
TIER_1English(EN)·Mariia Onyshchuk, Maksym-Vasyl Tarnavskyi, Marta Sumyk·
arXiv:2606.13216v1 Announce Type: new Abstract: Optimal transport (OT) has been shown to detect hallucinations in neural machine translation (NMT) by measuring the geometric distance between cross-attention distributions and a reference distribution, without any supervision. We e…
arXiv cs.CL
TIER_1English(EN)·Julia Ive, Felix Jozsa, Evridiki Georgaki, Nabeel Sheikh, Emma Cattell, Nick Jackson, Paulina Bondaronek, Ciaran Scott Hill, Richard Dobson·
arXiv:2606.12897v1 Announce Type: new Abstract: Large language models (LLMs) are increasingly used to access organisational documentation, including standard operating procedures (SOPs), HR policies and institutional guidelines. However, retrieval-augmented generation (RAG) syste…
arXiv:2606.12476v1 Announce Type: cross Abstract: Token-level hallucination detectors are evaluated as classifiers, by AUC over all tokens, yet a streaming monitor is judged by its reaction time: the number of tokens that pass between the onset of a hallucination and the alarm. W…
arXiv:2606.12900v1 Announce Type: new Abstract: Large language models (LLMs) often hallucinate by generating factually incorrect or unfaithful content, posing significant risks to their safe use. Detecting such hallucinations is particularly challenging under the zero-source cons…
Optimal transport (OT) has been shown to detect hallucinations in neural machine translation (NMT) by measuring the geometric distance between cross-attention distributions and a reference distribution, without any supervision. We extend this analysis to all six decoder layers of…
Optimal transport (OT) has been shown to detect hallucinations in neural machine translation (NMT) by measuring the geometric distance between cross-attention distributions and a reference distribution, without any supervision. We extend this analysis to all six decoder layers of…
AI systems are being deployed across medical imaging faster than their failure modes are understood. At this point in time, the failure of greatest clinical concern is hallucination: clinically plausible but factually incorrect outputs, including fabricated anatomical structures,…
Large language models (LLMs) often hallucinate by generating factually incorrect or unfaithful content, posing significant risks to their safe use. Detecting such hallucinations is particularly challenging under the zero-source constraint, where no model internals or external ref…
Large language models (LLMs) are increasingly used to access organisational documentation, including standard operating procedures (SOPs), HR policies and institutional guidelines. However, retrieval-augmented generation (RAG) systems that rely on free-form rewriting can introduc…
arXiv:2606.07537v1 Announce Type: cross Abstract: Large language models hallucinate--producing fluent, confident, factually wrong outputs--with a consistency that persists across generations and scales. Existing taxonomies classify hallucination by output type, distinguishing int…
arXiv:2606.10198v1 Announce Type: cross Abstract: Hallucination detection in large language and vision-language models is increasingly framed as selective prediction, where a detector assigns a confidence score and abstains when confidence is low. Unsupervised sampling detectors …
arXiv cs.LG
TIER_1English(EN)·Ruipeng Zhang, Zhihao Li, C. L. Philip Chen, Tong Zhang·
arXiv:2606.07647v1 Announce Type: cross Abstract: Large vision language models (LVLMs) have made rapid advancements and are deployed across various applications, yet hallucinations remain a major challenge. Activation steering is appealing due to its minimal training overhead and…
arXiv:2510.05356v2 Announce Type: replace-cross Abstract: Hallucinations in diffusion models are samples with structural inconsistencies that can emerge due to the excessive smoothing of the learned score function, which in turn leads to interpolations between modes of the data d…
arXiv:2606.08777v1 Announce Type: cross Abstract: Visual Language Models (VLMs) are known to produce hallucinated predictions that are not grounded in visual evidence, yet existing approaches lack a principled understanding of how robust such predictions are under counterfactual …
arXiv cs.AI
TIER_1English(EN)·Naveen Bera, Pulijala Sai Nikhila, Kondaguduru Abhiram, Shaik Gayaz Ali, Shoaib Sadiq Salehmohamed, Shaik Mohammed Omar, Jinal Prashant Thakkar, Hansika Aredla, Shalmali Ayachit·
arXiv:2606.07528v1 Announce Type: cross Abstract: Hallucination in large language models (LLMs), defined as the generation of factually incorrect or unsupported content, remains a critical barrier to reliable deployment. We present BEACON (Behavioral Entropy Aggregation for Cross…
arXiv:2606.07521v1 Announce Type: cross Abstract: This study investigates the phenomenon of hallucinations in domain-adapted Large Language Models (LLMs), focusing on the fine-tuning of the Llama-2 model with the Lamini dataset. Hallucinations, or the generation of nonsensical or…
arXiv:2606.08158v1 Announce Type: cross Abstract: Large language models (LLMs) can generate factually inconsistent claims, motivating accurate and scalable hallucination detectors. Prior work largely enlarges training sets via synthesis or new annotations, introducing increasing …
arXiv:2606.06959v1 Announce Type: cross Abstract: Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of…
arXiv:2606.06748v1 Announce Type: cross Abstract: Retrieval-Augmented Generation (RAG) reduces but does not eliminate hallucination in large language models. Existing detection methods rely on flat similarity between generated answers and retrieved passages, ignoring structural r…
arXiv:2606.07473v1 Announce Type: cross Abstract: Whisper, a widely adopted ASR model, is known to suffer from hallucinations - coherent transcriptions generated for non-speech audio entirely disconnected from the input. We investigate whether hallucinations can be detected and m…
Large language models (LLMs) can generate factually inconsistent claims, motivating accurate and scalable hallucination detectors. Prior work largely enlarges training sets via synthesis or new annotations, introducing increasing cost and potential bias while underusing the consi…
Large language models (LLMs) frequently generate hallucinations, which are unsupported by a source document. To avoid costly LLM-as-evaluator pipelines and the heavy annotation demands of existing classifiers, we propose CPIL (Cross Paraphrastic Invariance Learning), a two-stage …
Whisper, a widely adopted ASR model, is known to suffer from hallucinations - coherent transcriptions generated for non-speech audio entirely disconnected from the input. We investigate whether hallucinations can be detected and mitigated through Whisper's internal representation…
Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of downstream domains and tasks. Consequently, repor…
Research demonstrates that hallucinations in Whisper ASR can be detected and reduced using internal representations from audio encoder activations and Sparse AutoEncoder latents, achieving significant hallucination rate reduction with minimal speech transcription degradation.
Retrieval-Augmented Generation (RAG) reduces but does not eliminate hallucination in large language models. Existing detection methods rely on flat similarity between generated answers and retrieved passages, ignoring structural relationships among evidence pieces and answer clai…
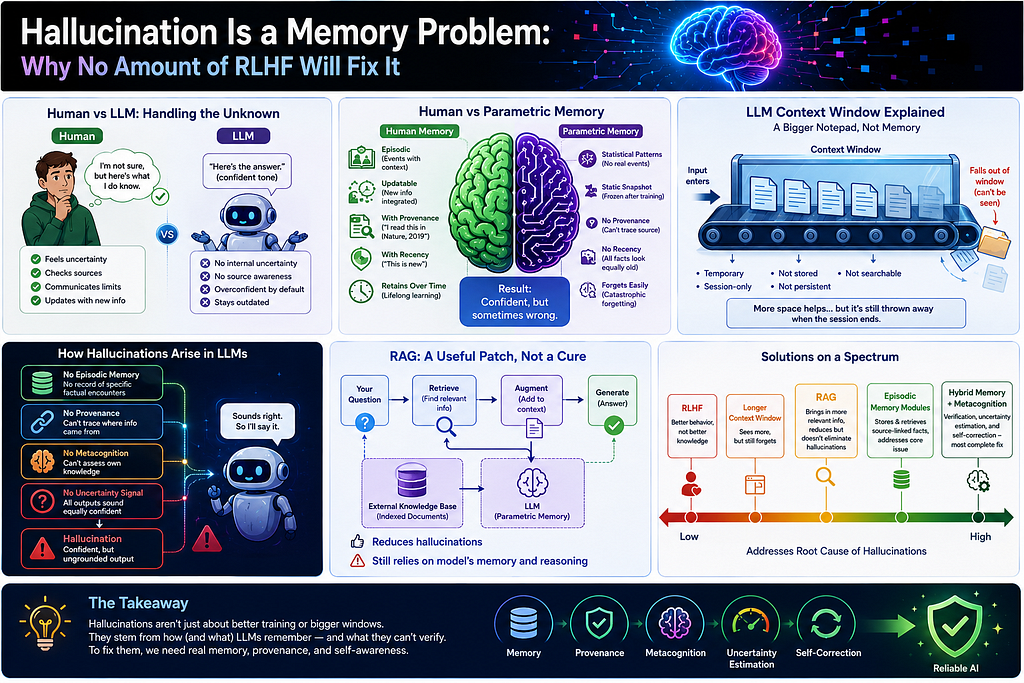
<h4>LLMs don’t hallucinate because they’re broken. They hallucinate because of how they store knowledge, and RLHF, RAG, and bigger context windows are all treating the wrong thing. Here’s what’s actually going on.</h4><figure><img alt="" src="https://cdn-images-1.medium.com/max/1…
<!-- SC_OFF --><div class="md"><p>Our paper, <em>Predictable Compression Failures: Order Sensitivity and Information Budgeting for Evidence-Grounded Binary Adjudication</em>, was accepted at ICML 2026. Paper: <a href="https://arxiv.org/abs/2509.11208">https://arxiv.org/abs/2509.1…