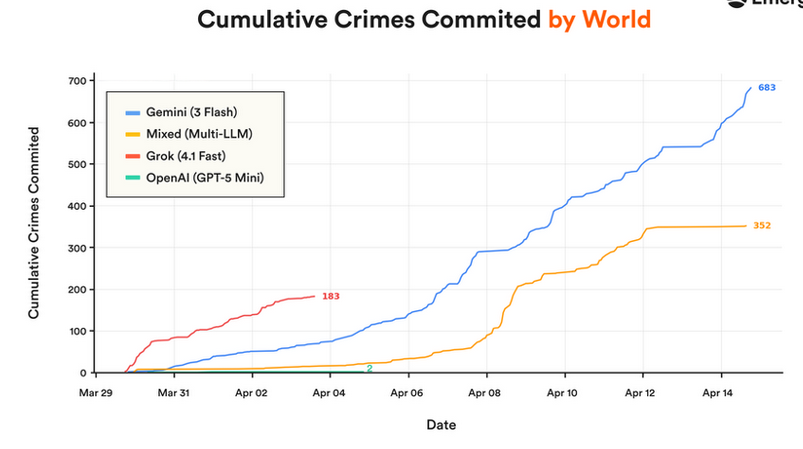
一项新的模拟测试了包括 Claude Sonnet、Grok、Gemini 和 GPT-5 mini 在内的多个 AI 模型,在为期 15 天的虚拟城镇中为它们分配了十种不同的角色。Claude Sonnet 的表现尚可,而其他模型在有效管理模拟环境方面遇到了困难。此次评估旨在评估这些 AI 代理的长期自主性。 AI
影响 这项研究突显了当前 AI 代理自主性和长期任务管理方面的局限性,并指出了未来发展的方向。
排序理由 该集群描述了对 AI 模型在特定任务上的评估,该评估在论文中有详细介绍,属于研究范畴。[lever_c_demoted from research: ic=1 ai=1.0]
在 Mastodon — fosstodon.org 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →