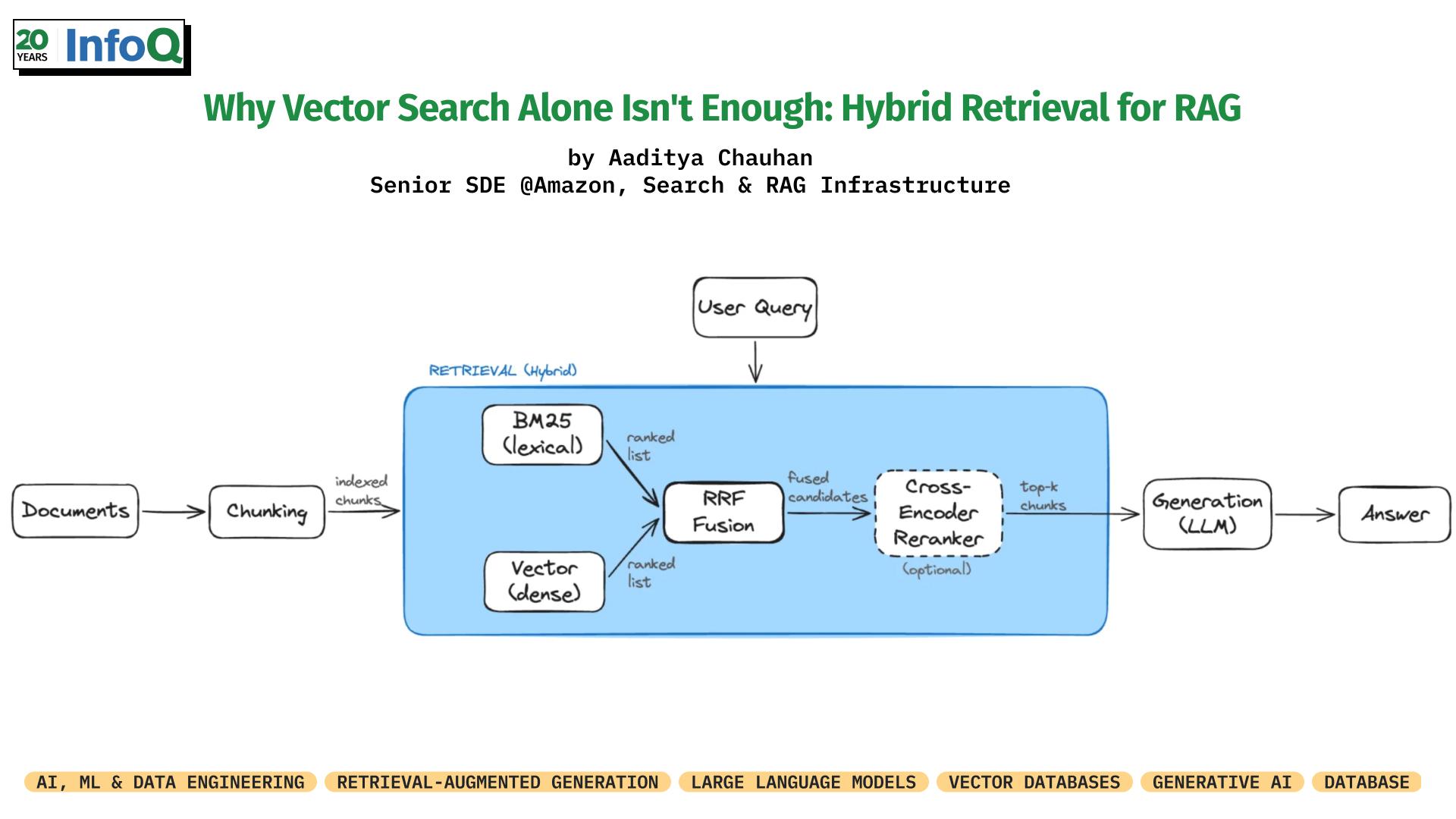
为了提高检索增强生成(RAG)管道的准确性,仅依赖嵌入式模型是不够的。开发人员应结合使用BM25,并将其与倒数排名融合(RRF)相结合,并考虑添加交叉编码器重新排序阶段以获得最佳检索质量。这种多方面的方法旨在显著提高RAG系统的性能。 AI
影响 通过建议结合嵌入式模型与BM25和RRF的混合方法来提高检索准确性,从而增强RAG系统的性能。
排序理由 该集群讨论了一种提高AI模型性能的技术方法,特别是针对RAG管道,这属于研究范畴。[lever_c_demoted from research: ic=1 ai=1.0]
在 Mastodon — fosstodon.org 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →