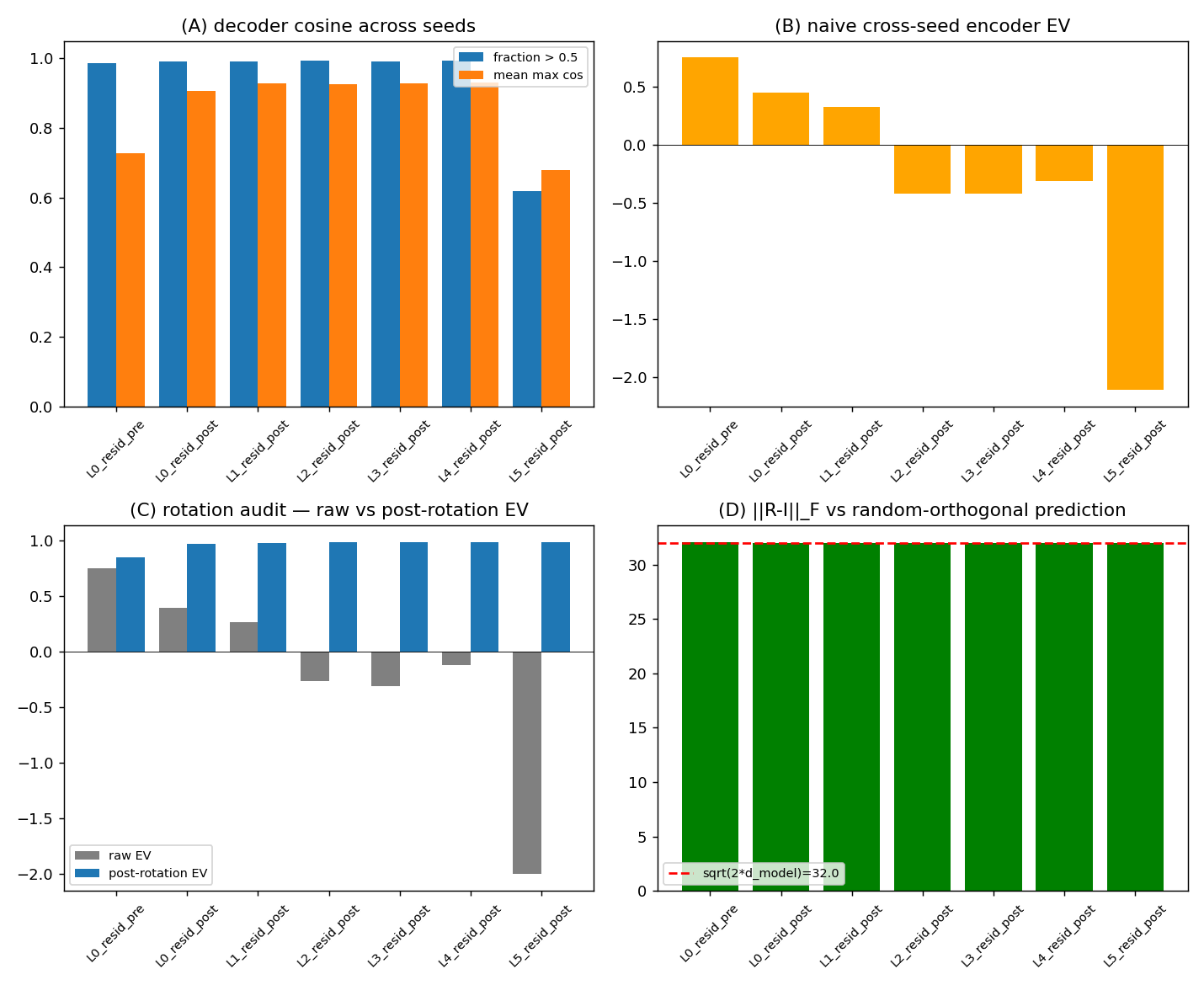
研究人员发现,虽然相同架构的独立训练的 Transformer 模型学习到的特征相似,但它们的内部激活表示会以随机量进行旋转。这种“多态性”意味着在一个模型中识别出的特征在另一个模型中是无法理解的,除非进行校正。将在一个模型上训练的稀疏自编码器 (SAE) 应用于另一个模型会导致灾难性的重建失败,但这可以通过一次矩阵乘法来对齐基底来修复。 AI
影响 理解内部模型表示可能有助于提高 AI 系统的可解释性和可控性。
排序理由 详细介绍内部模型表示新发现的学术论文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →