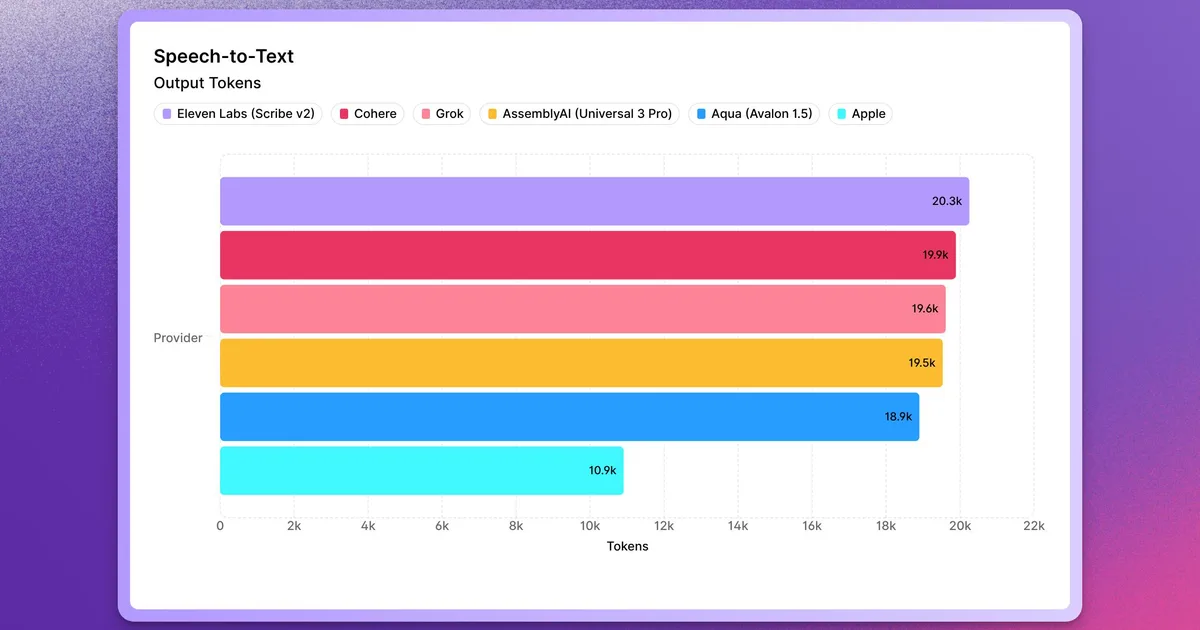
近期对语音转文本模型的比较显示,Eleven Labs 的 Scribe v2 表现最佳,得分为 20,251。Cohere 的模型紧随其后,得分为 19,885,Grok 的得分为 19,611。AssemblyAI 的 Universal 3 Pro 得分为 19,530,Aqua 的 Avalon 1.5 得分为 18,899。Apple 的本地模型也被包含在内,得分为 10,907。 AI
影响 为语音转文本模型性能提供了基准,有助于开发人员选择 STT 解决方案。
排序理由 这是对语音转文本模型的比较,而不是新前沿模型的发布或重大的行业事件。
在 Mastodon — mastodon.social 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →