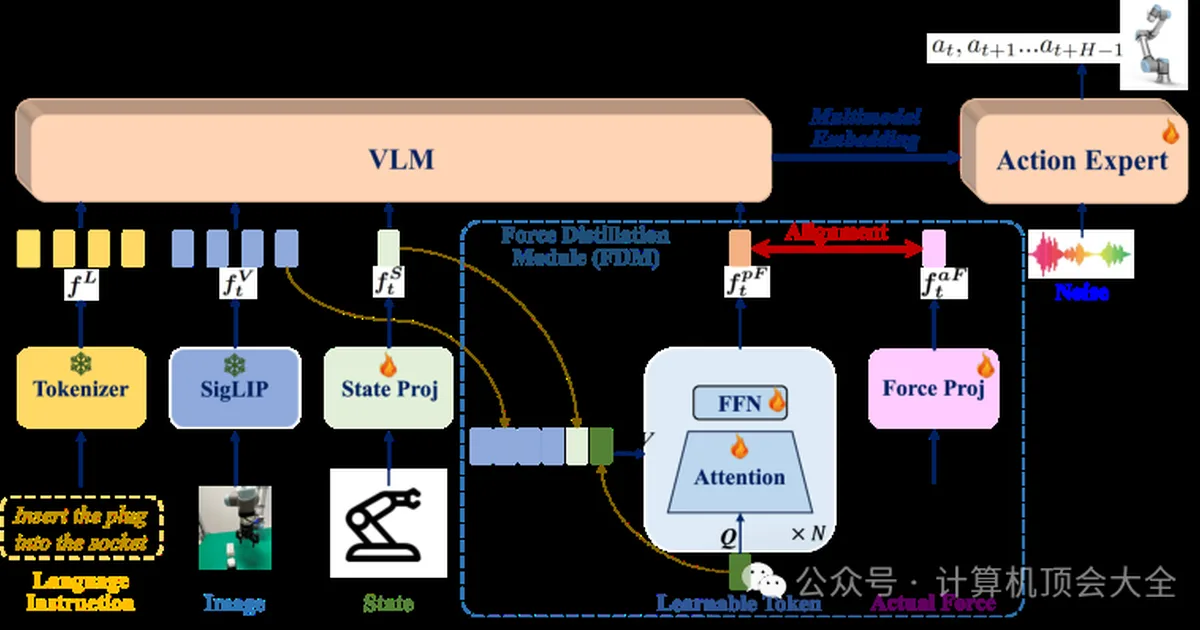
新加坡国立大学的研究人员开发了FD-VLA,这是一种新颖的视觉-语言-动作(VLA)模型,旨在改善接触密集型任务中的机器人操作。与主要依赖视觉和语言线索的先前VLA模型不同,FD-VLA通过蒸馏机制整合了力信息。这使得模型能够在训练期间学习潜在的力表示,并在推理期间从视觉和本体感觉数据中预测力线索,从而减少对物理力传感器的依赖。在真实机器人平台上进行的实验表明,FD-VLA的性能显著优于没有力感知能力或使用原始力信号的模型,突显了学习到的力表示在擦白板、按按钮和插入插头等任务中的有效性。 AI
影响 通过整合力反馈增强机器人操作能力,有望提高复杂物理任务的性能。
排序理由 该集群描述了一篇关于机器人操作新模型的学术论文。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →