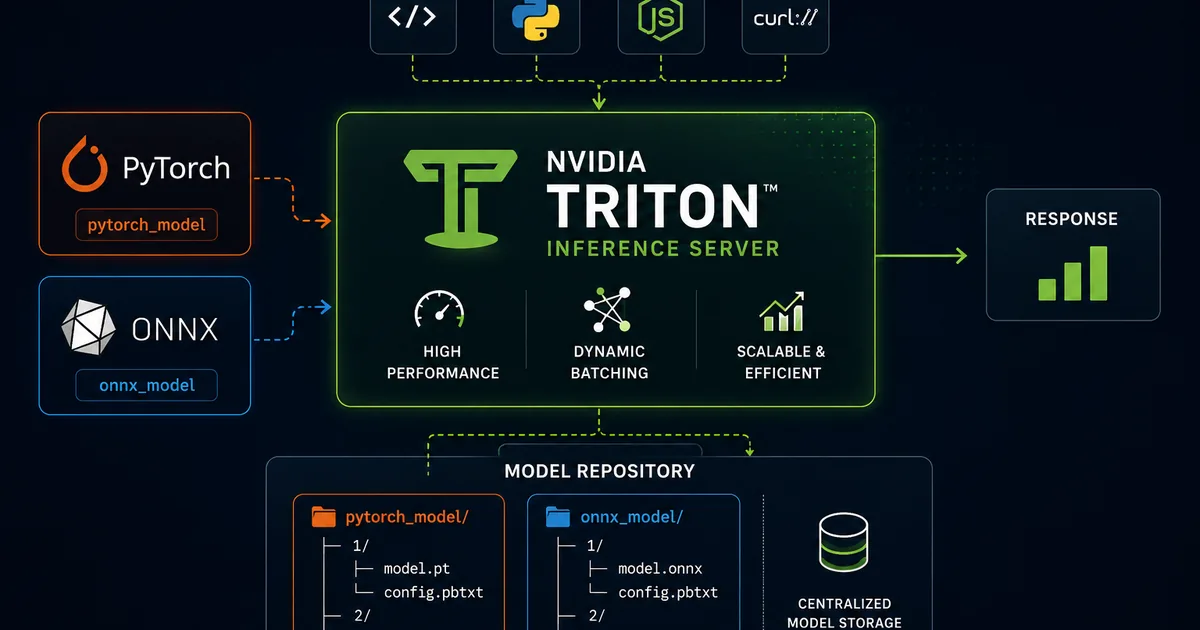
本文详细介绍了如何使用 NVIDIA 的 Triton 推理服务器在单个推理服务器上同时运行 PyTorch 和 ONNX 模型。该过程在本地 Mac 环境中演示,无需 GPU,突显了该设置在 MLOps 实践中的灵活性和可访问性。 AI
影响 能够在一台服务器上高效部署各种 AI 模型,减少基础设施需求并简化 MLOps 工作流程。
排序理由 文章描述了一个关于在特定推理服务器上部署现有模型的实用技术指南,属于工具范畴。
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →