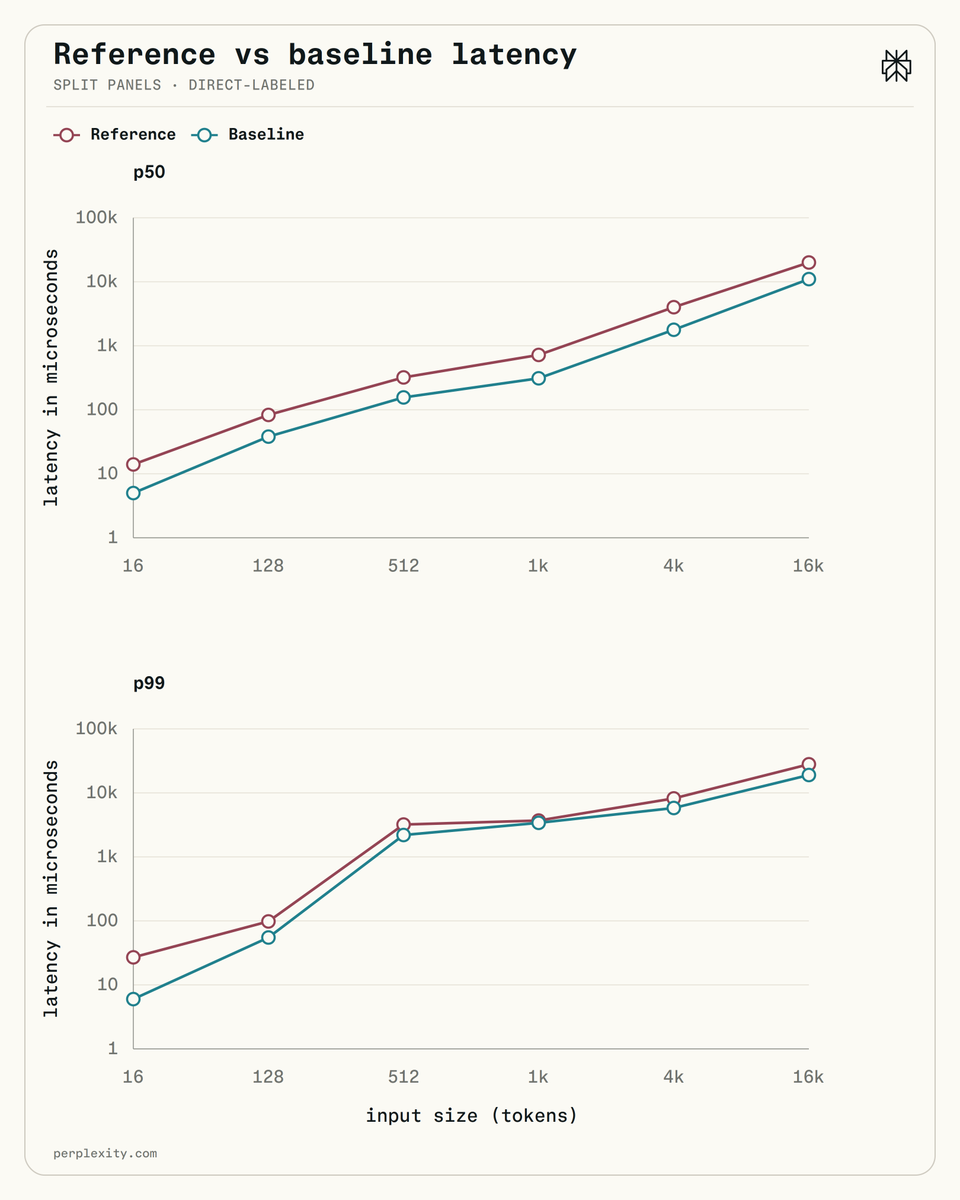
Perplexity AI 已开源一款新的 Unigram 分词器,旨在显著提高 CPU 性能。与 HuggingFace 的实现相比,这款新分词器的延迟降低了 5 倍;与 SentencePiece C++ 相比,延迟降低了 2 倍。优化后的分词器针对具有大型词汇表(如 XLM-RoBERTa 的 250K 标记 Unigram 词汇表)的场景,这些场景常用于排名和检索任务。 AI
影响 通过降低 CPU 上的分词延迟来加速 AI 模型的推理。
排序理由 为 AI 产品开源了性能优化的组件。
AI 生成摘要 · Google Gemini · 来自 4 个来源。 我们如何撰写摘要 →