新的分析表明,大型语言模型中约 48% 的端到端延迟归因于预填充阶段,其余 52% 来自解码过程。预填充阶段进一步分为两个操作:预填充扩展,涉及写入新上下文和 KV 标记;以及缓存读取,重复使用先前交互中的现有 KV 缓存。 AI
影响 了解 LLM 的延迟细分对于优化推理速度和成本至关重要。
排序理由 第三方来源对 LLM 性能特征的分析。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
新的分析表明,大型语言模型中约 48% 的端到端延迟归因于预填充阶段,其余 52% 来自解码过程。预填充阶段进一步分为两个操作:预填充扩展,涉及写入新上下文和 KV 标记;以及缓存读取,重复使用先前交互中的现有 KV 缓存。 AI
影响 了解 LLM 的延迟细分对于优化推理速度和成本至关重要。
排序理由 第三方来源对 LLM 性能特征的分析。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
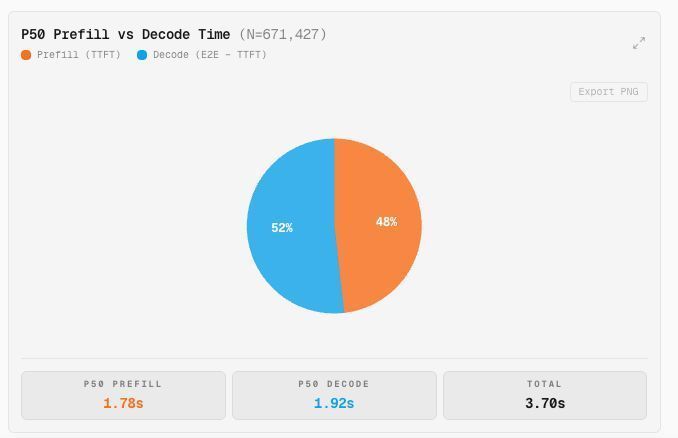
PDOOM ALERT 🚨 : ~48% of e2e LLM latency is prefill, ~52% is decode. Prefill itself breaks into 2 ops: 🟠 Prefill extend (cache write) — ingests new context/files, writes fresh KV tokens 🟠 Cache read — reuses existing KV cache from prior turns https://t.co/zzKrZFZKhX