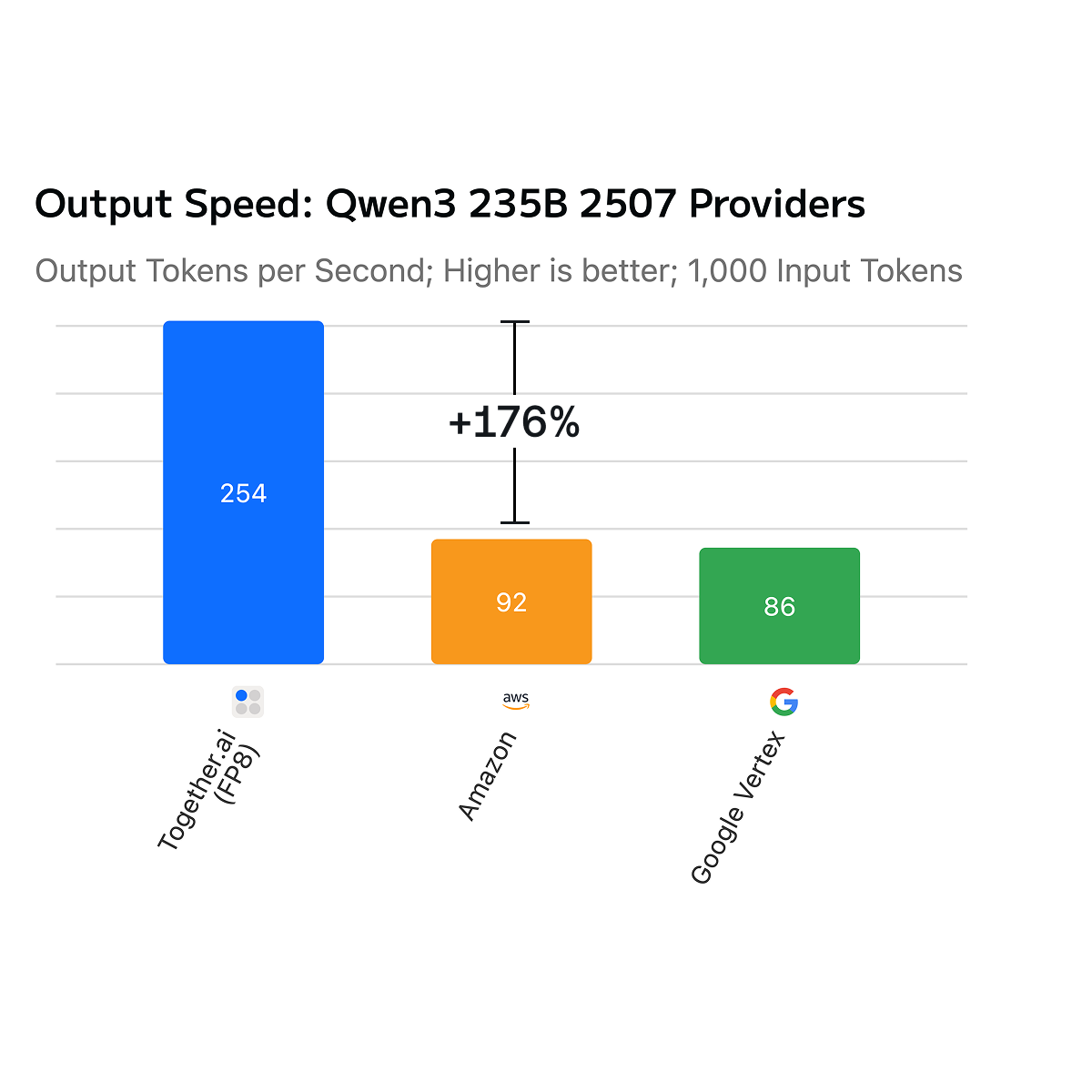
Together AI 推出了名为 Dedicated Container Inference 的新服务,旨在优化自定义生成媒体模型的部署和性能。该平台处理自动扩展、排队和流量隔离等复杂的编排任务,使团队能够专注于模型逻辑。该服务已展现出显著的推理速度提升,部分客户的性能提升高达 2.6 倍。此外,Together AI 还宣布了其推理平台的进步,通过利用下一代 GPU 硬件和优化的内核,为顶级开源模型实现了高达 2 倍的服务器无服务器推理速度。 AI
影响 加速自定义和开源 AI 模型的部署和推理,可能降低专业 AI 应用的成本并提高其可访问性。
排序理由 该集群宣布了来自知名 AI 基础设施提供商的新产品和现有服务的重大性能改进。
- Creatify
- Dedicated Container Inference
- DeepSeek-R1
- DeepSeek-V3.1
- GPT-OSS
- Hedra
- Kimi-K2
- NVIDIA Blackwell
- Qwen3
- Together AI
AI 生成摘要 · Google Gemini · 来自 3 个来源。 我们如何撰写摘要 →