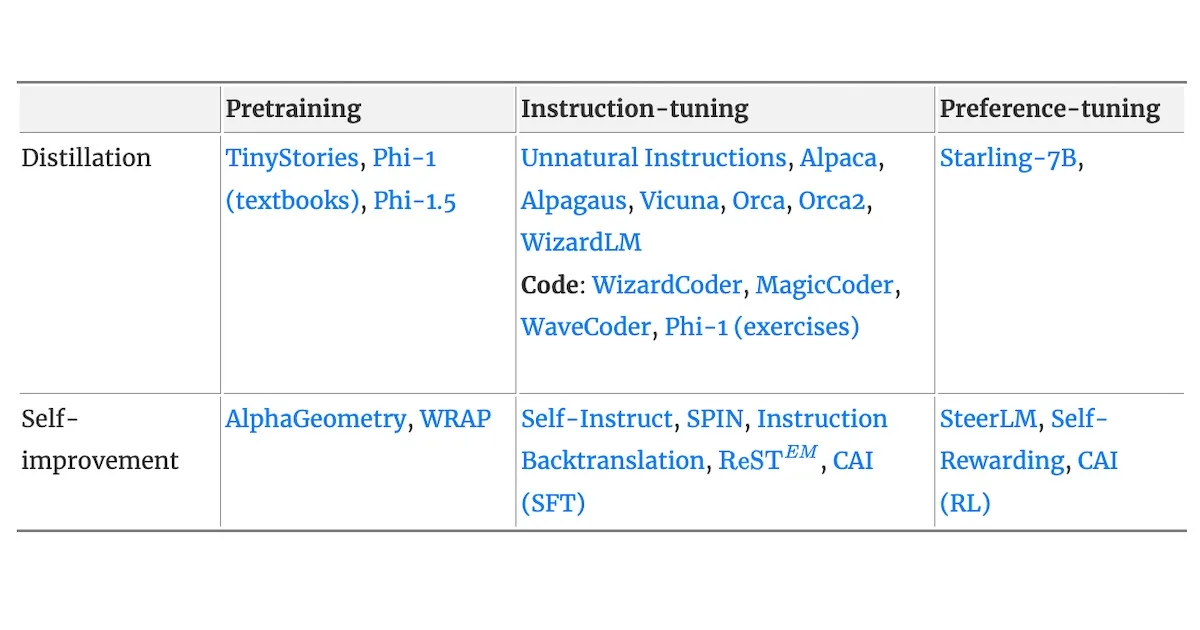
合成数据,由模型或模拟而非真实世界来源生成,为微调AI模型提供了比人工标注更快、更具成本效益的替代方案。这种方法可以提高模型性能和泛化能力,同时减轻隐私和版权问题。生成合成数据的两种主要方法包括从更强大的模型进行蒸馏以及模型自身改进其输出的自改进技术。这些方法可应用于预训练、指令微调和偏好微调,以增强模型能力的各个方面。 AI
排序理由 文章讨论了用于AI模型微调的合成数据生成的研究论文和技术。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
合成数据,由模型或模拟而非真实世界来源生成,为微调AI模型提供了比人工标注更快、更具成本效益的替代方案。这种方法可以提高模型性能和泛化能力,同时减轻隐私和版权问题。生成合成数据的两种主要方法包括从更强大的模型进行蒸馏以及模型自身改进其输出的自改进技术。这些方法可应用于预训练、指令微调和偏好微调,以增强模型能力的各个方面。 AI
排序理由 文章讨论了用于AI模型微调的合成数据生成的研究论文和技术。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →
Overcoming the bottleneck of human annotations in instruction-tuning, preference-tuning, and pretraining.