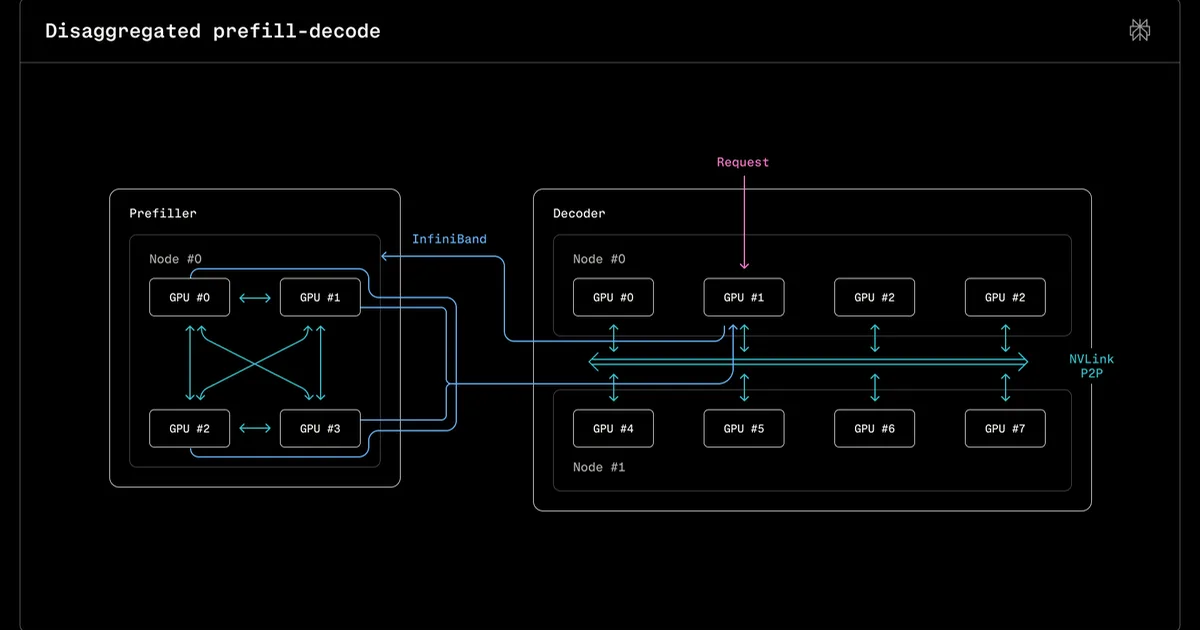
Perplexity 发布了一项研究,详细介绍了他们如何在 NVIDIA 的 GB200 NVL72 Blackwell 机架上部署大型语言模型,特别是 Qwen3 235B。研究结果表明,与之前的 NVIDIA 硬件相比,GB200 平台在大型模型推理方面提供了显著的改进,具有更低的延迟和更高的吞吐量。这项研究强调了 GB200 在训练和高吞吐量推理方面的能力,特别是对于专家混合(MoE)模型。 AI
影响 NVIDIA 的 GB200 Blackwell 平台在 LLM 推理速度和成本效益方面显示出显著的提升,可能加速大型模型的部署。
排序理由 该集群包含 Perplexity 发布的研究,内容涉及 LLM 推理硬件。
AI 生成摘要 · Google Gemini · 来自 4 个来源。 我们如何撰写摘要 →