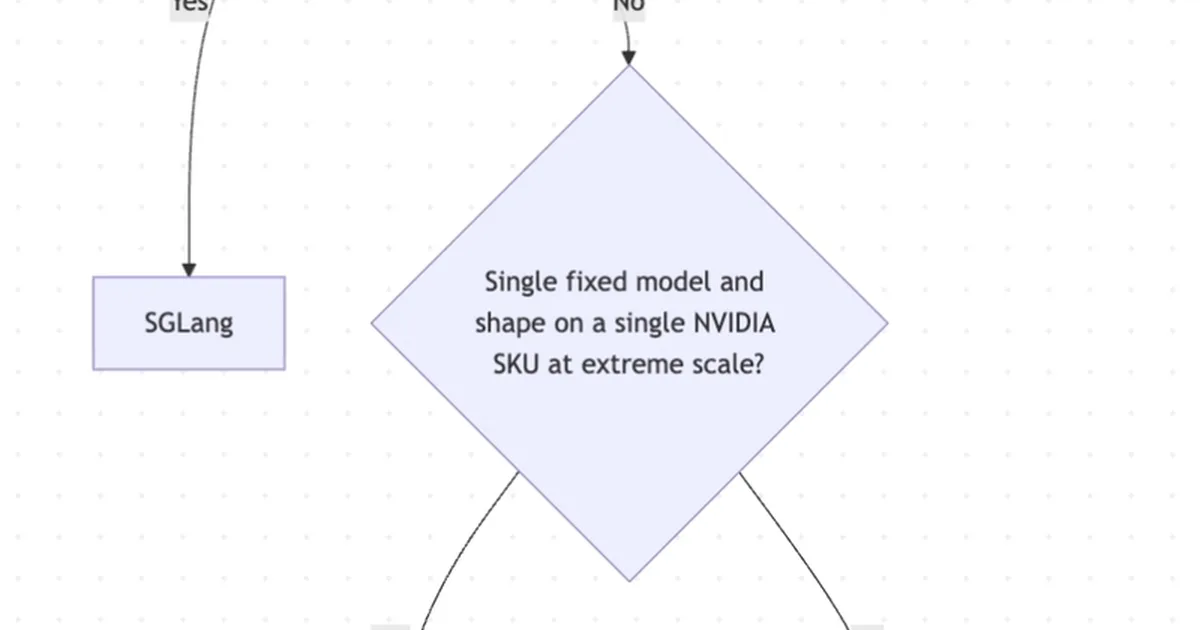
本文提供了一份优化 vLLM 部署的指南,重点关注影响性能和成本的三个关键配置决策。文章详细介绍了静态 KV 缓存分配如何导致 GPU 内存不足错误,并强调了选择正确的服务框架、管理 KV 缓存与模型权重的内存预算以及配置分块预填充和前缀缓存等批处理策略的重要性。该指南还概述了常见的故障模式,并为有效的 vLLM 运行提供了架构见解。 AI
影响 为使用 vLLM 高效部署和管理大型语言模型提供了关键的运营见解。
排序理由 文章为现有的 AI 服务框架提供了运营指导和配置细节。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →