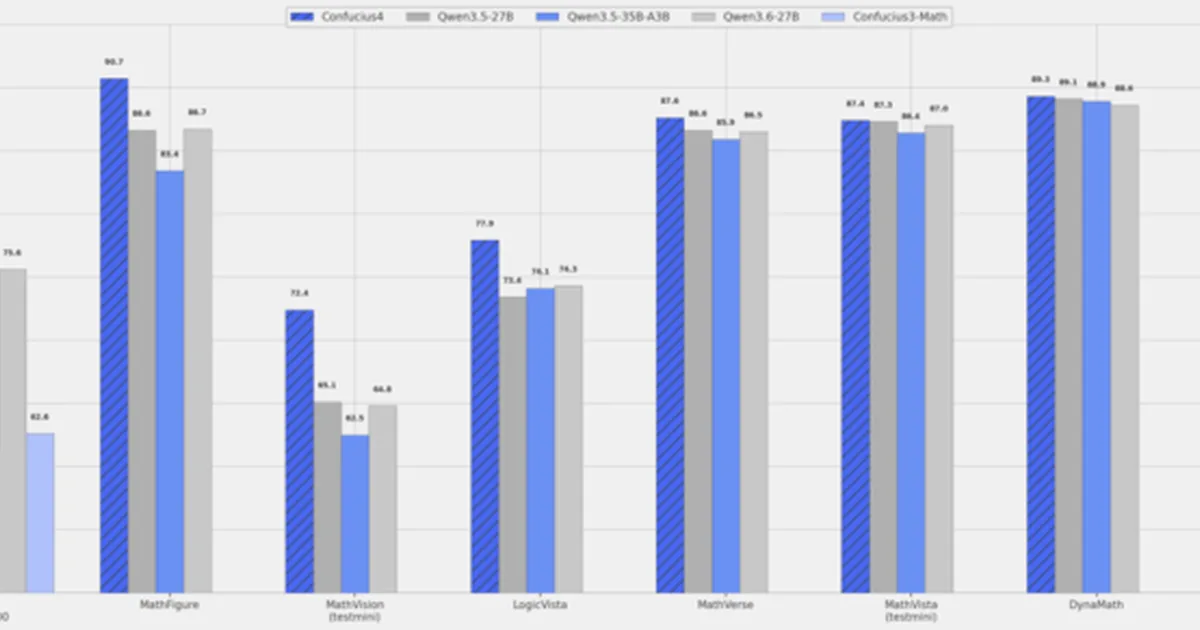
网易有道宣布对其“子曰4”大语言模型进行重大升级,现已进入多模态时代,支持文本、图像和音频交互。该公司正开源其核心多模态和文本到语音(TTS)模型,旨在降低开发者的落地成本。新模型在视觉数学推理方面展现出最先进的性能,并将推理链输出长度缩短了43.2%,从而降低了推理成本。 AI
影响 降低了开发者在多模态和语音合成方面的门槛,可能加速AI Agent的开发和采用。
排序理由 这是来自一家AI领域主要科技公司的重磅产品发布和开源计划。[lever_c_demoted from significant: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →