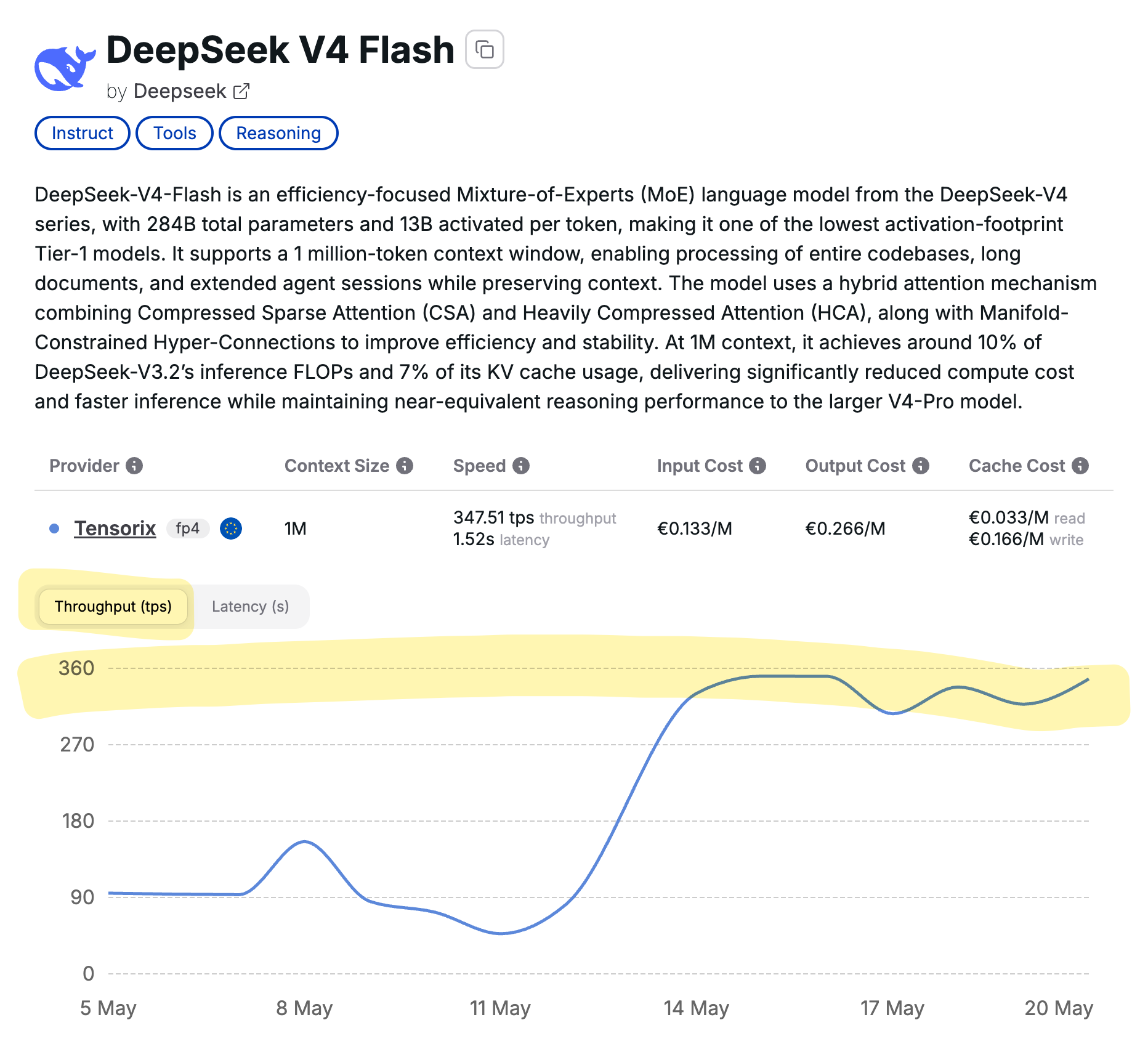
DeepSeek V4 Flash,DeepSeek V4 模型的新迭代,已展示出令人印象深刻的性能指标。它实现了每秒 350 个 token 的吞吐量,延迟约为 1.5 秒。这一进展归功于 Tensorix 和 Cortecs,并对欧盟的 AI 发展产生了影响。 AI
影响 DeepSeek V4 Flash 的新性能基准提供了对 LLM 吞吐量和延迟能力的见解。
排序理由 该集群详细说明了特定 AI 模型迭代的性能指标,这属于研究里程碑。[lever_c_降级自研究:ic=1 ai=1.0]
在 Mastodon — fosstodon.org 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →