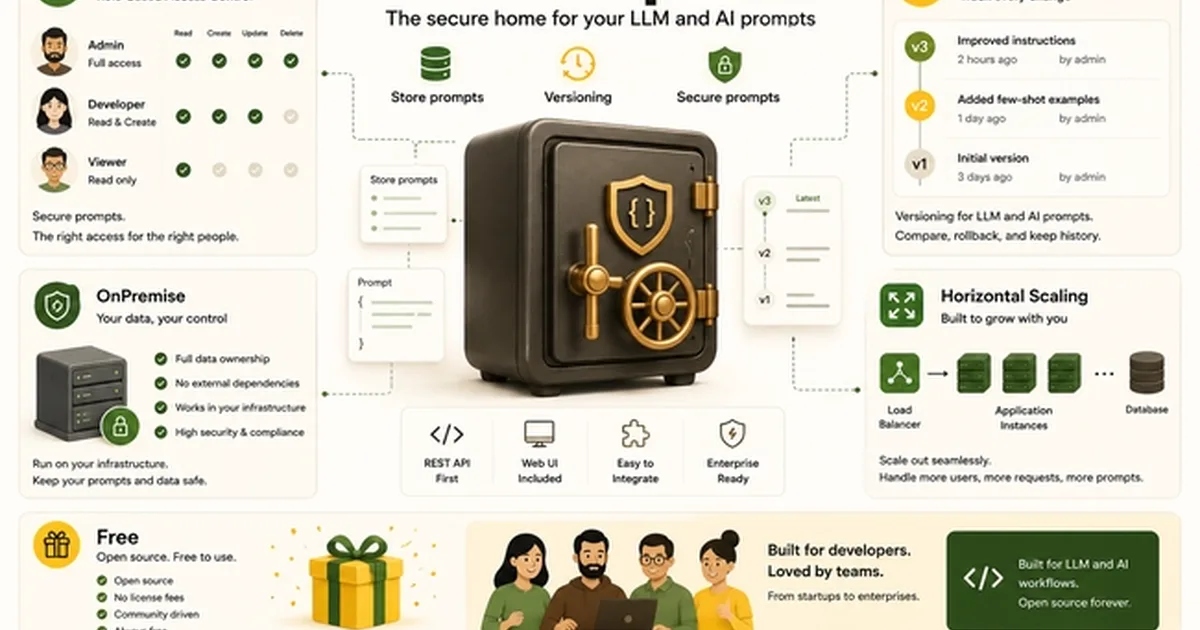
本教程解释了如何使用Python构建自定义评分框架,以客观地对大型语言模型的提示变体进行基准测试,超越主观评估。它详细介绍了设置开发环境、定义清晰的评估标准以及使用OpenAI客户端库和pytest等工具。第二篇文章讨论了工程团队在将提示作为应用程序逻辑进行管理和版本控制时面临的挑战,并强调PromptMan是一个健壮的、开源的、本地部署的解决方案,其REST API优先的设计可实现安全且可扩展的提示管理。 AI
影响 为开发人员提供了系统评估和管理LLM提示的实用指南,这对于生产级别的AI应用程序至关重要。
排序理由 该集群包含一个关于构建LLM提示基准测试框架的教程和一个关于提示管理工具的评测,属于研究和工具类别。
- Flowise
- LangSmith
- Notion
- Obsidian
- Prompt Engineering
- Promptfoo
- PromptHub
- PromptLayer
- PromptMan
- PromptPal
- PromptPerfect
- Anthropic
- OpenAI
- Python
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →