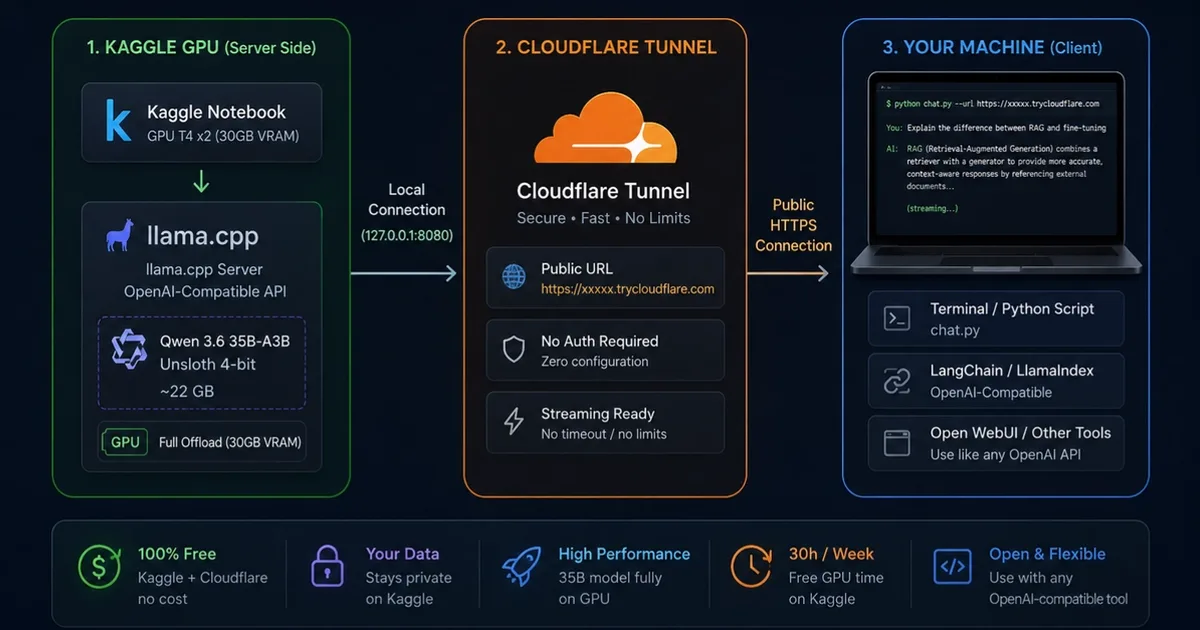
一位开发者创建了一种方法,可以在免费的 Kaggle GPU 上运行一个 350 亿参数的多模态大语言模型,克服了此类平台的典型限制。该解决方案使用 4 位量化的 Qwen3.6-35B-A3B 模型,托管在 Kaggle 的 T4 GPU 上,每次会话最多可运行 12 小时。它利用 llama.cpp 进行推理,并提供一个 OpenAI 兼容的 API。Cloudflare Quick Tunnel 提供了一个稳定的公共 URL,支持 token 流式传输,这一点优于其他免费隧道服务。 AI
影响 使开发者能够在免费的云 GPU 上运行强大的大语言模型,绕过了昂贵的硬件或 API 费用。
排序理由 该集群描述了一个在免费平台上运行现有开源大语言模型的技术设置和指南,而不是一个新的模型发布或重要的行业事件。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →