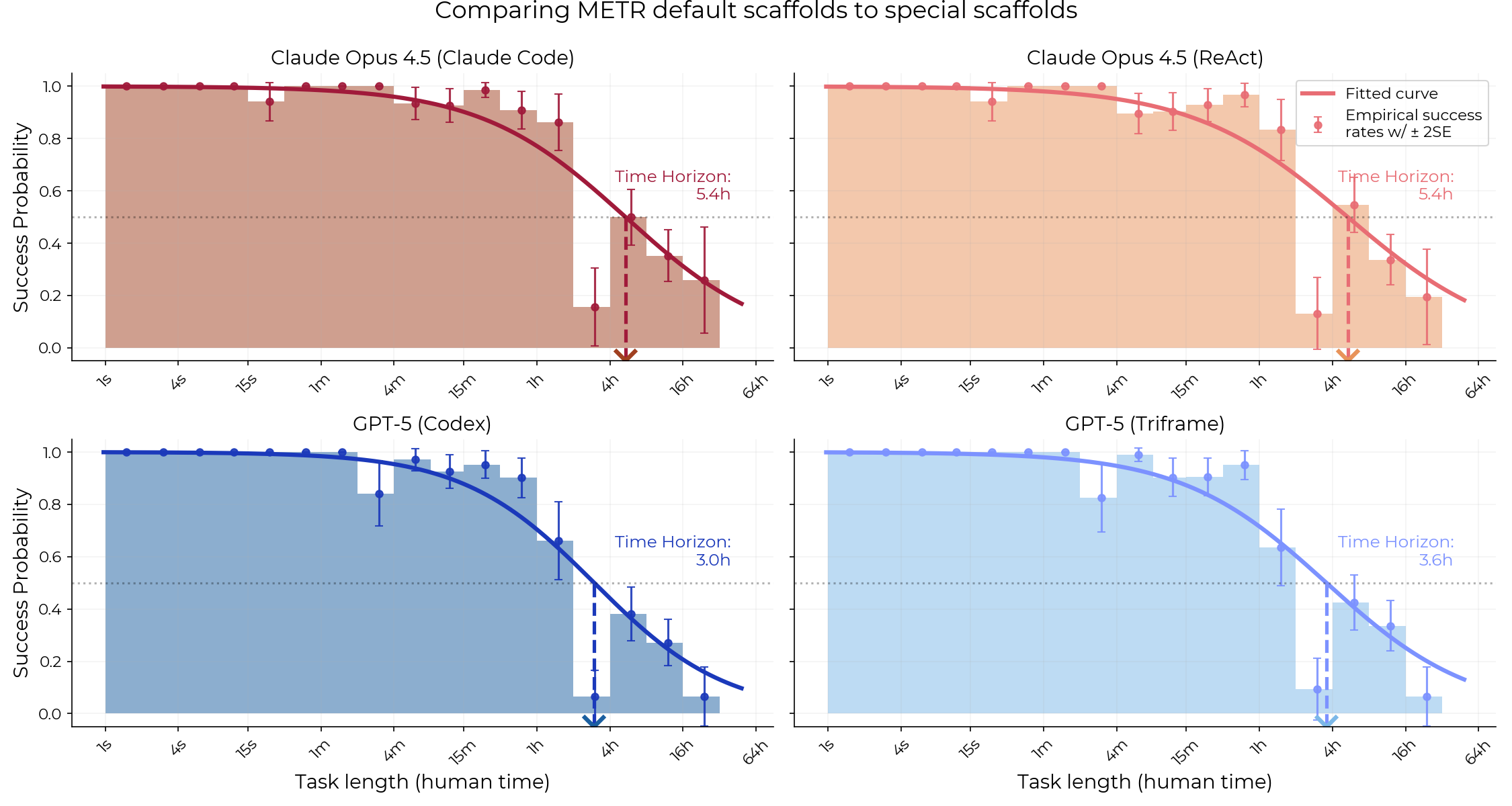
METR(模型评估与威胁研究)最近的一项评估发现,在测量 Opus 4.5 和 GPT-5 等模型的时间跨度能力时,像 Claude Code 和 Codex 这样的专用脚手架并不比通用脚手架(Triframe 和 ReAct)有显著优势。尽管这些专用脚手架针对软件工程任务进行了优化,并进行了更详细的提示,但它们并未显示出统计学上的显著优势。该研究通过使用通用和专用脚手架,对 METR 现有的任务套件进行模型性能比较,并对专用代理进行了微调以进行评估。 AI
排序理由 该集群基于一篇评估 AI 模型能力的学术论文,使用了特定的方法论。
在 METR (Model Evaluation & Threat Research) 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →