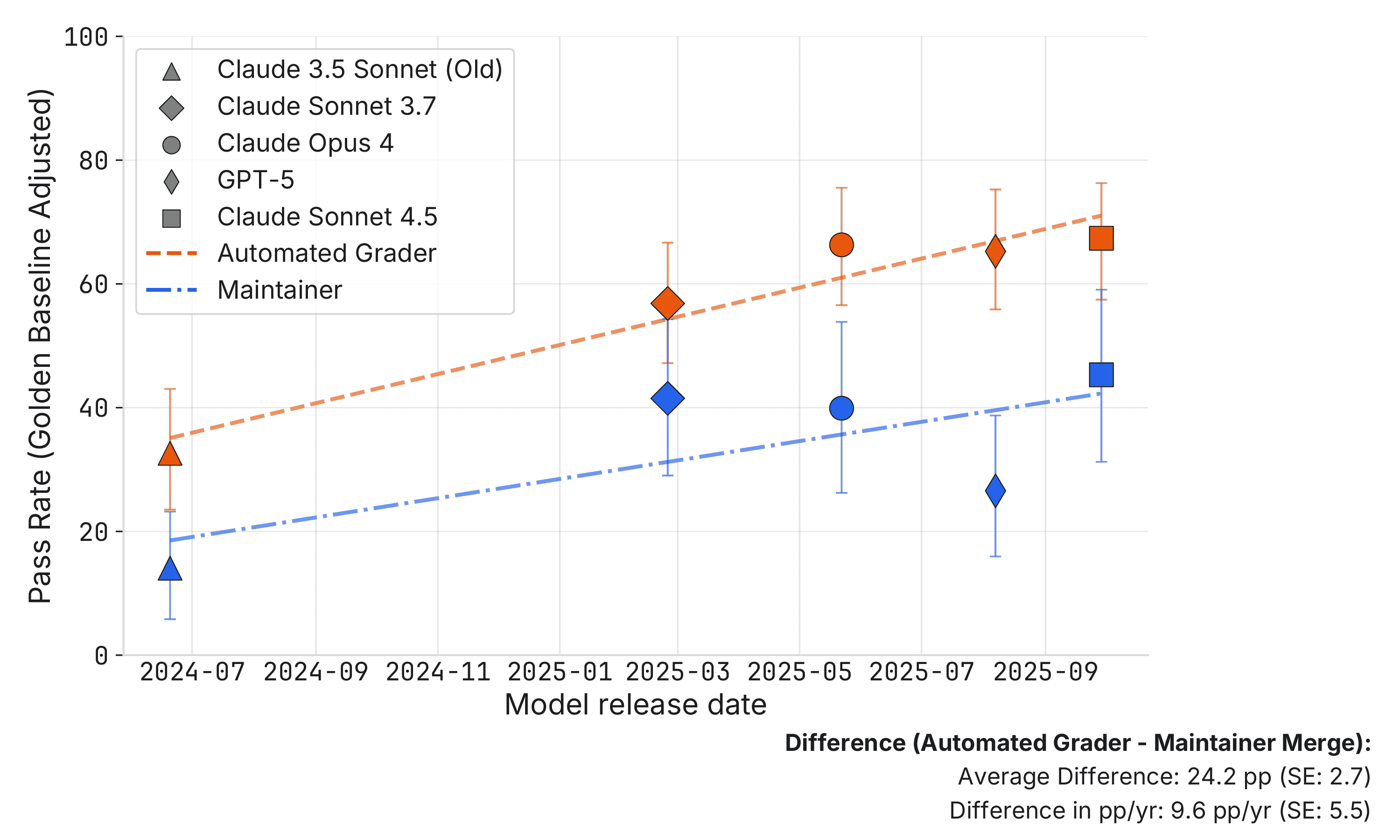
来自 METR 的一项新研究显示,大约一半由 AI 代理生成的、通过了 SWE-bench 自动化测试的拉取请求 (PR) 不会被人类维护者接受。这种差异表明,当前的基准分数可能高估了 AI 代码生成工具的实际可用性。研究强调,AI 代理缺乏人类开发者受益的迭代反馈循环,对基准结果的简单解读可能会导致对 AI 能力的期望过高。 AI
排序理由 该集群基于评估 AI 模型在软件工程基准上性能的学术论文。
在 METR (Model Evaluation & Threat Research) 阅读 →
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →