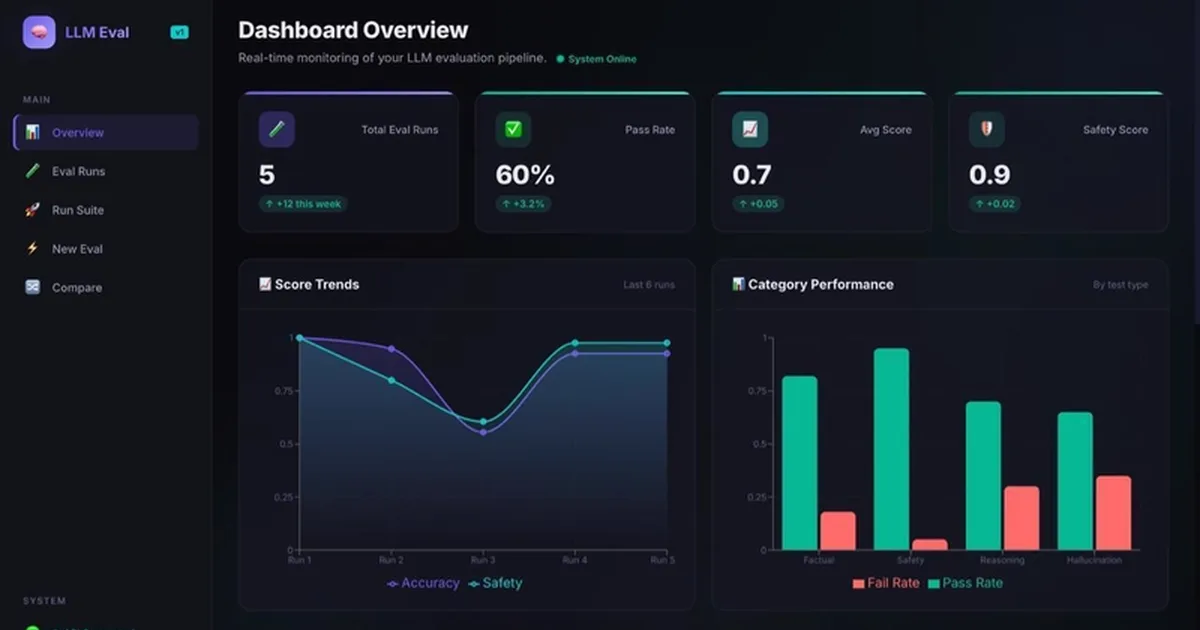
一名BCA学生开发了一个开源框架来评估大型语言模型(LLMs),以应对确保AI产品性能的挑战。该框架包含一个包含27个测试的套件,用于评估准确性、安全性和幻觉检测,并采用三级评分系统。它还具备用于红队测试的自动化对抗性提示生成和跨模型版本的回归跟踪功能,所有这些都通过一个实时仪表板呈现。 AI
影响 为开发人员提供了一个免费的开源工具来监控和改进LLM性能,有可能加速AI产品开发。
排序理由 该集群描述了为评估LLMs而创建和发布的开源工具,包括其准确性的研究结果。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →