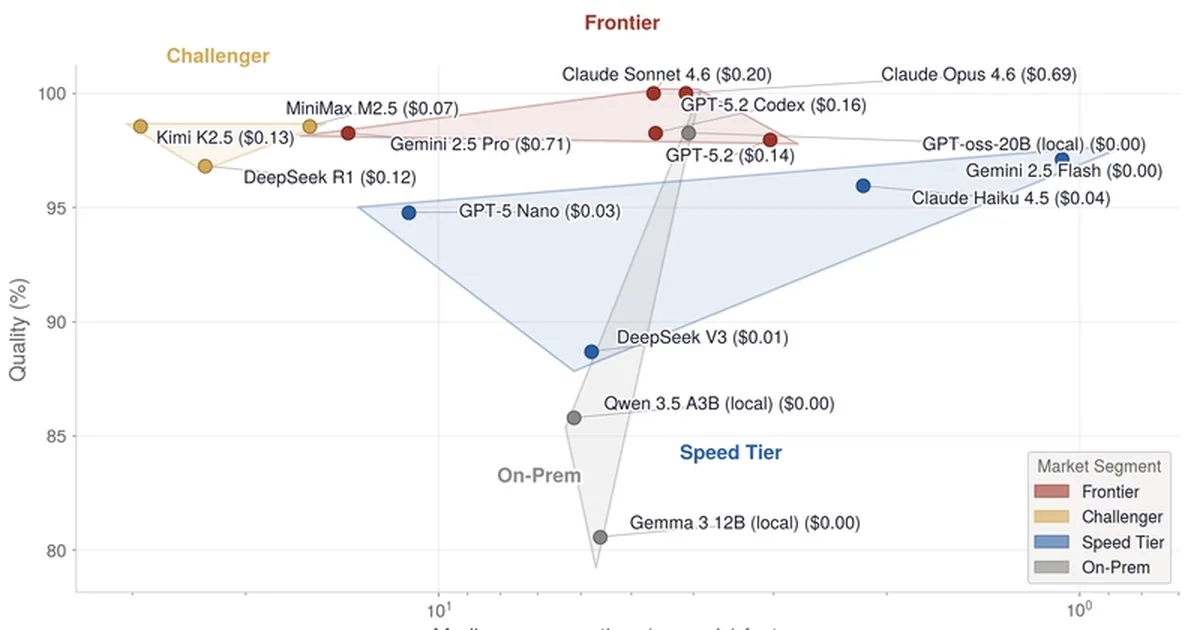
最近的一项基准测试在 38 个真实世界编码任务上测试了 15 个 LLM,结果表明,结合不同模型的路由策略比选择单一顶级模型更有效。研究发现,Gemini Flash 和 GPT-oss-20b 等更便宜的模型足以胜任许多任务,以较低的成本实现了高准确率。对于更复杂的任务,Opus 和 Sonnet 等模型表现出色,该基准测试强调了根据任务复杂性、速度和成本对 LLM 进行分层部署的方法。 AI
影响 证明了使用成本效益高的模型的层级路由策略可以在许多任务上媲美甚至超越单一高端模型的性能。
排序理由 该集群描述了在真实世界任务上对现有 LLM 的基准测试,而不是新的模型发布或重大的行业事件。[lever_c_demoted from research: ic=1 ai=1.0]
- Codex CLI
- DeepSeek R1
- DeepSeek V3
- Gemini Flash
- GPT-5-Nano
- GPT-oss-20b
- Haiku
- Kimi K2.5
- MiniMax M2.5
- Opus
- R1
- Sonnet
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →