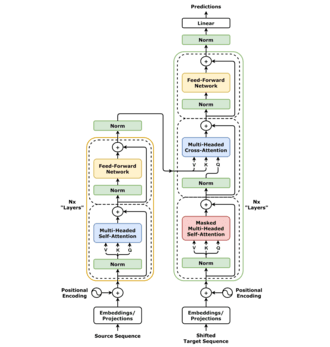
Researchers from Tsinghua University and Alibaba have developed ViT³, a novel Vision Transformer architecture that achieves linear computational complexity. This breakthrough allows for efficient processing of high-resolution images, making advanced visual understanding feasible on edge devices. The work was presented as an oral paper at CVPR 2026. AI
影响 Enables efficient high-resolution image understanding on edge devices, potentially expanding AI capabilities in resource-constrained environments.
排序理由 The cluster describes a new research paper detailing a novel model architecture presented at a major computer vision conference. [lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →