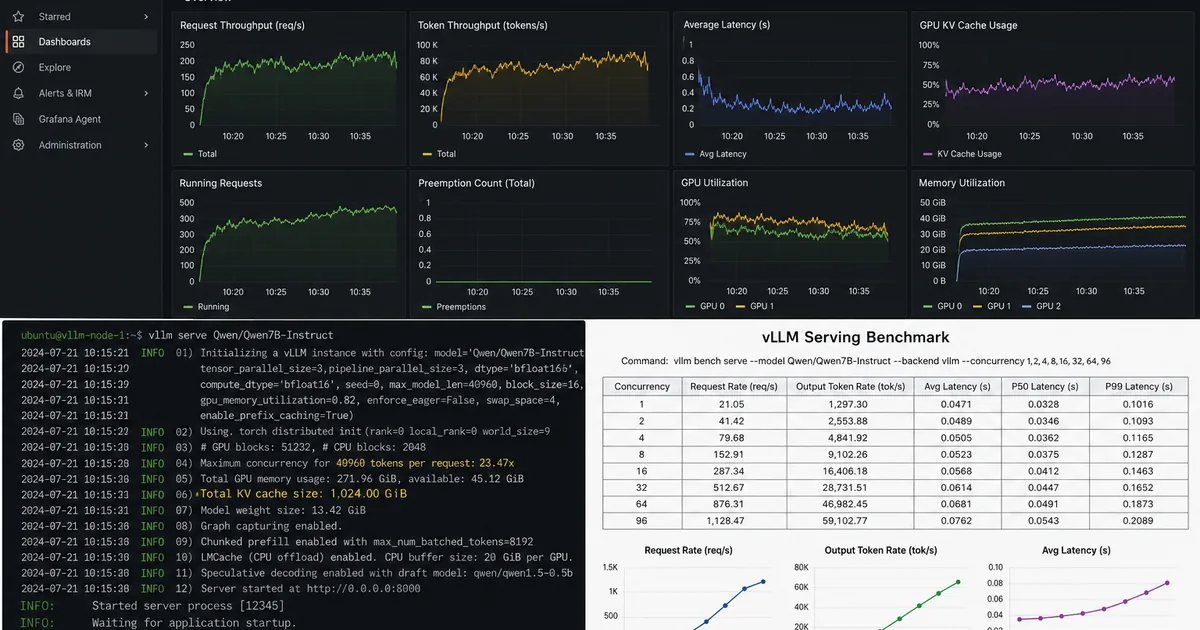
一位开发者详细介绍了他们为在生产语音AI系统中处理高并发而优化vLLM的过程。该设置利用了一个三节点GPU集群,配备NVIDIA A4500和A100显卡,用于服务一个基于Qwen的模型。此优化旨在提高AI服务的效率和吞吐量。 AI
影响 为管理高吞吐量推理工作负载的AI运维人员提供了具体的技术见解。
排序理由 文章描述了在生产环境中对现有工具(vLLM)进行的特定技术优化,而不是新版本发布或重大行业事件。
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →