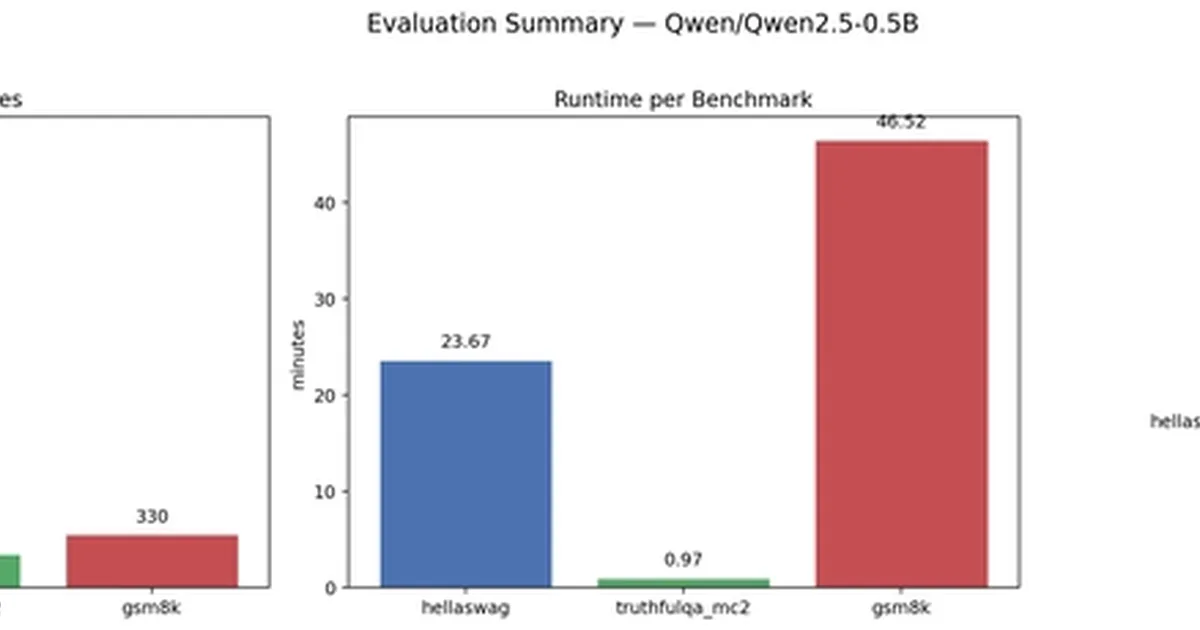
这篇博文详细介绍了一种经济高效的评估大型语言模型的方法,证明了运行全面的基准测试的成本可以低于一美元。作者使用免费的Google Colab T4实例在三个不同的任务上测试了Qwen2.5-0.5B模型:GSM8K用于数学推理,HellaSwag用于常识,TruthfulQA-MC2用于真实性。实验重点是测量运行时间和成本,利用lm-evaluation-harness并进行特定调整以优化性能和降低费用,例如限制生成令牌的长度。 AI
影响 证明了严格的LLM评估是可及且负担得起的,从而能够更广泛的模型测试和比较。
排序理由 文章详细介绍了一种使用标准基准评估LLM的方法,重点关注成本和运行时间,这构成了对评估技术的研究。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →