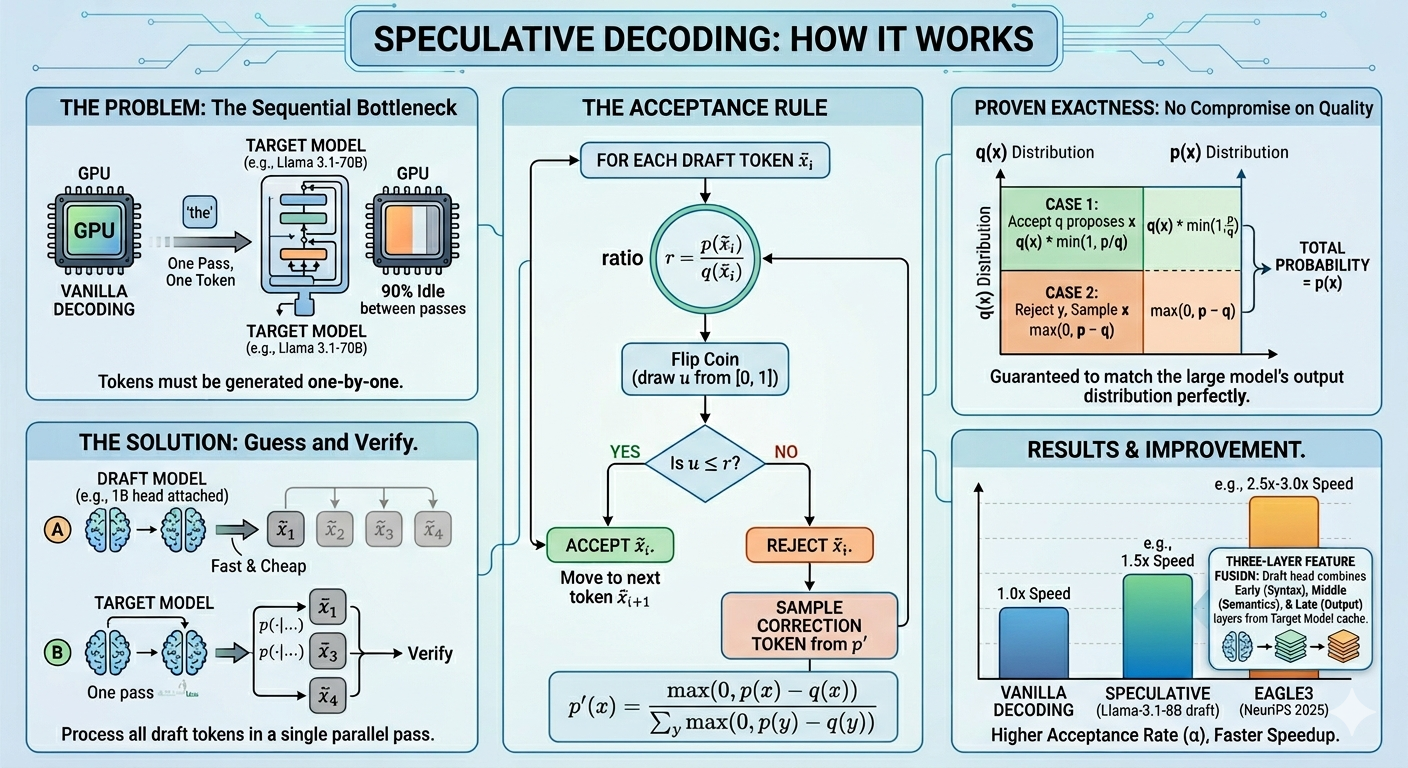
一种名为推测性解码的新技术允许大型语言模型通过提前预测然后验证来更有效地生成文本。该方法旨在降低生成每个 token 的计算成本,目前这需要完整的正向传播。通过让 LLM 进行猜测和检查,该过程可以显著加快文本生成速度。 AI
影响 这项技术可以显著降低 LLM 推理的计算成本,使其更快、更易于访问。
排序理由 该集群描述了一种提高 LLM 效率的新研究技术。[lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →