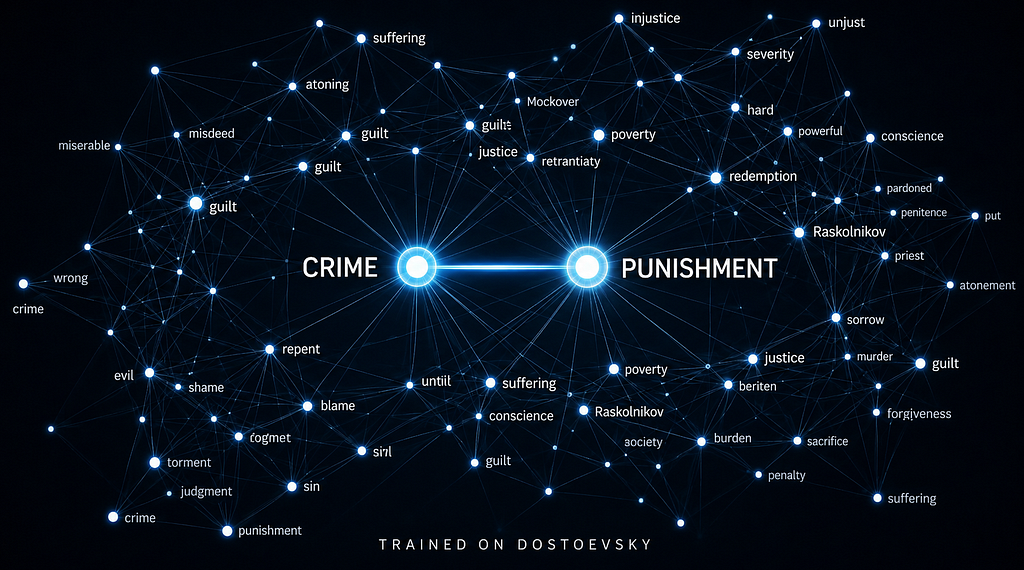
The author details their process of building word embeddings from scratch, using Dostoevsky's novels as a corpus of nearly one million words. This step follows their previous work on character-level tokenization and aims to represent words as dense vectors that capture semantic relationships, moving beyond simple frequency counts. The article explains the mathematical concepts behind embeddings and highlights the limitations of earlier NLP models like one-hot encodings, which struggled with semantic understanding and data sparsity. AI
影响 Demonstrates a foundational NLP technique for representing word meaning, crucial for building more sophisticated language models.
排序理由 The article describes a personal project implementing a core NLP technique (word embeddings) from scratch, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →