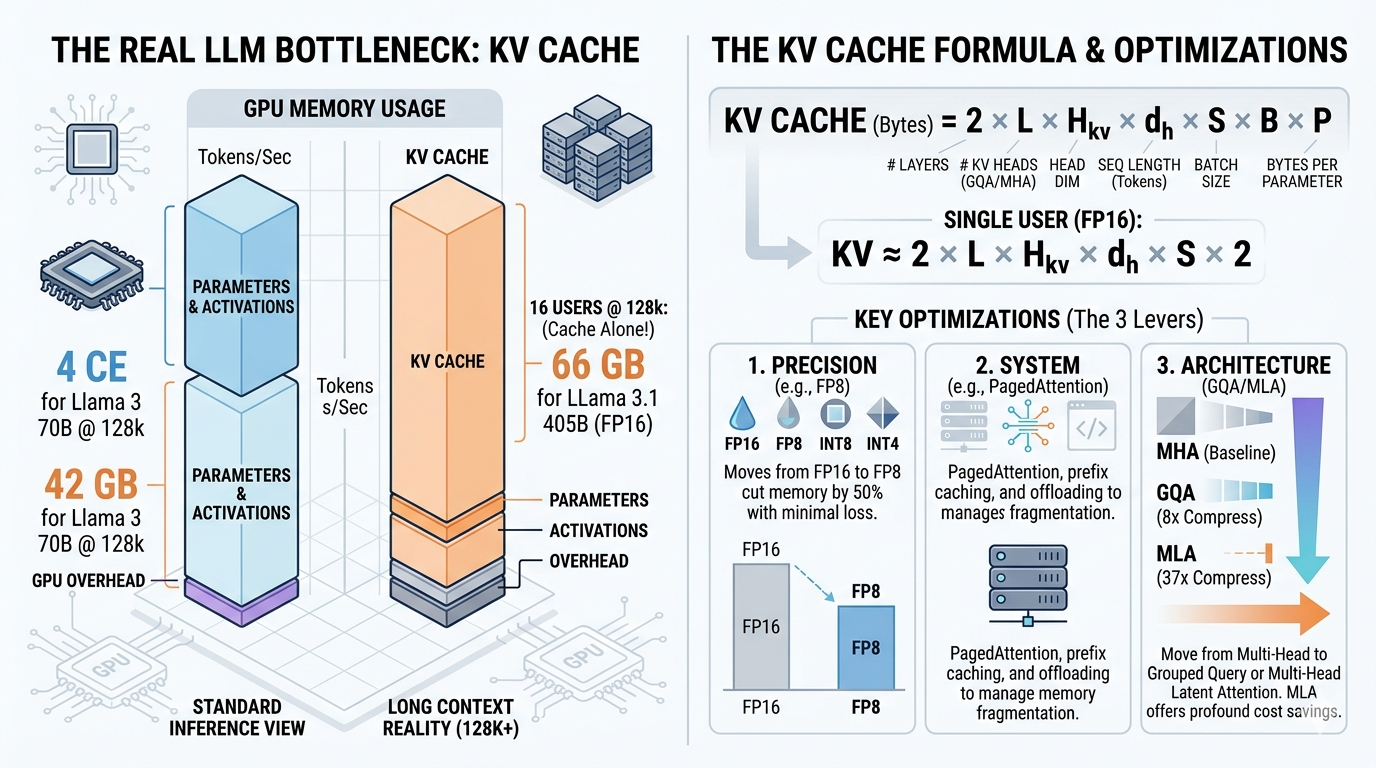
大型语言模型利用KV缓存来加速推理,通过存储先前计算出的键(key)和值(value)向量,而不是为每个新令牌重新计算它们。该技术在初始、计算密集型的“预填充”(prefill)阶段(缓存构建时)之后,显著加快了令牌生成速度。然而,KV缓存以增加内存使用量为代价来减少计算量,缓存大小随上下文长度线性增长,并且在大规模部署时可能超过模型权重。 AI
影响 解释了LLM推理的核心优化技术,影响模型效率和部署成本。
排序理由 该集群解释了LLM中的一个技术概念(KV缓存),详细说明了其机制和权衡,这符合研究或技术文档的特点。
- ChatGPT
- Claude
- grouped-query attention
- KV caching
- LLMs
- multi-query attention
- Paged attention
- Qwen 2.5 72B
- Transformer
- Llama 3.1 405B
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →