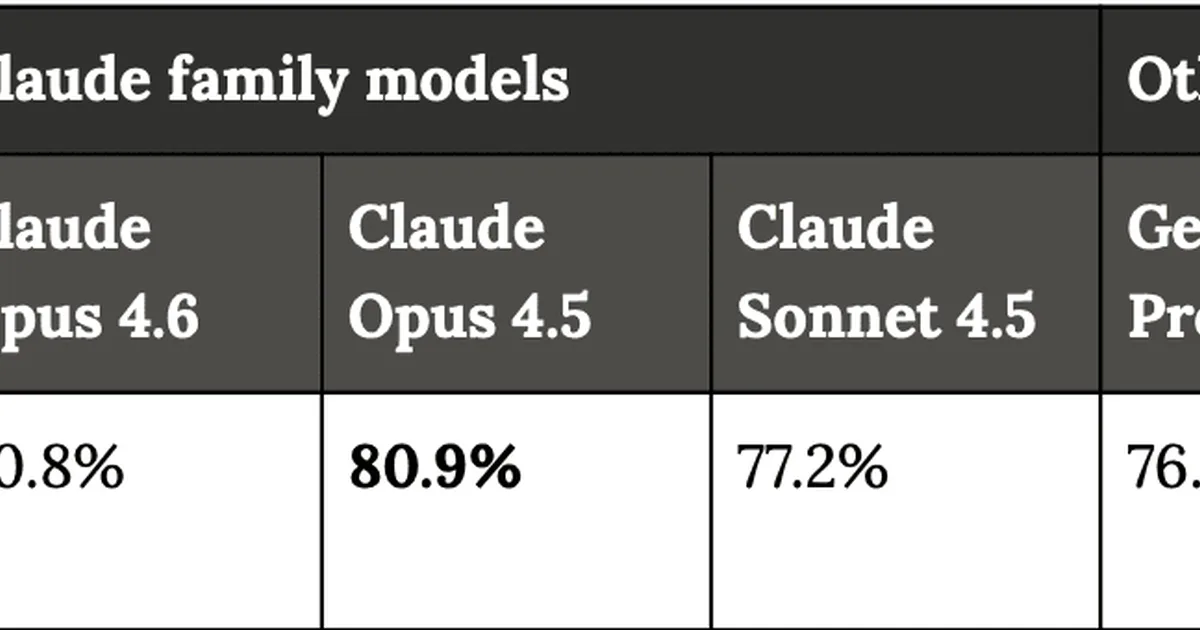
AI实验室之间的模型评估方法不一致,导致基准测试结果无法比较,并可能做出有缺陷的发布决策。OpenAI、Anthropic和Google DeepMind等公司已经改变了它们的评估设置,包括试验次数和使用的工具,使得直接比较变得困难。作者建议将评估转移给第三方审计机构,类似于其他高风险行业,以确保可靠性和透明度。 AI
影响 不一致的基准测试阻碍了对AI进展的可靠跟踪和风险评估,因此需要标准化的第三方评估。
排序理由 文章讨论了AI模型评估方法的问题并提出了解决方案,属于研究类别。[lever_c_demoted from research: ic=1 ai=1.0]
- Anthropic
- Claude 4
- Gemini 3
- Google DeepMind
- GPQA
- GPT-5
- OpenAI
- Opus 4.5
- Opus 4.6
- Opus 4.7
- SWE-bench Verified
- Gemini 2.5
AI 生成摘要 · Google Gemini · 来自 1 个来源。 我们如何撰写摘要 →