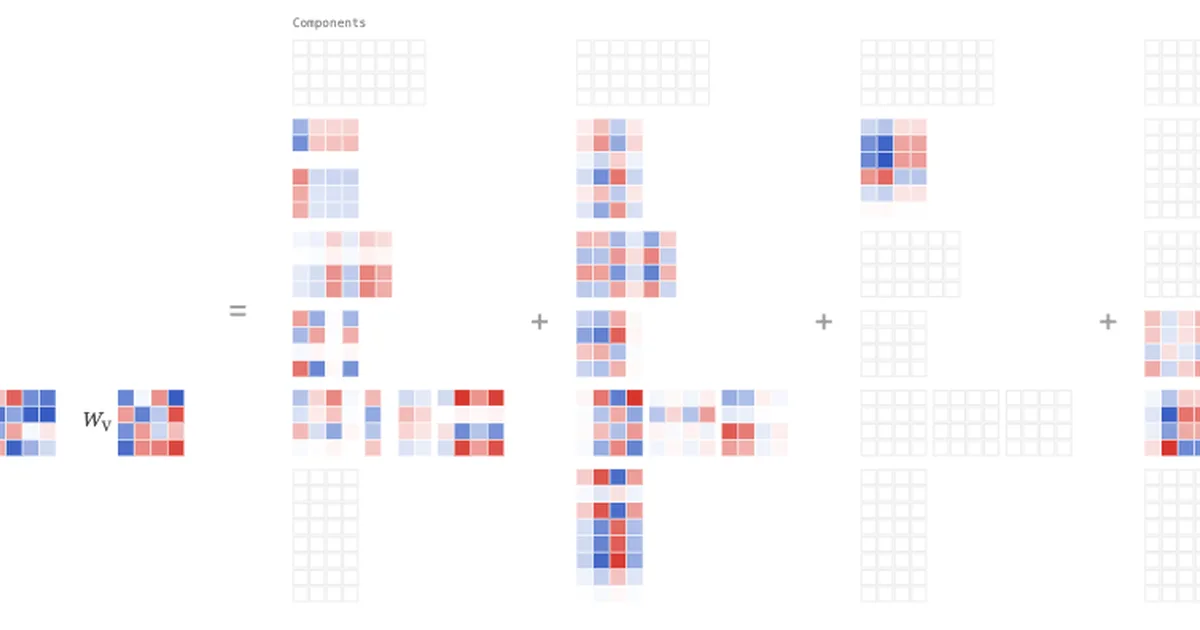
研究人员引入了对抗性参数分解(VPD),一种改进的语言模型参数解释方法。这项新技术建立在先前工作如随机参数分解(SPD)和基于归因的参数分解(APD)的基础上。VPD能够分解注意力层,这是可解释性方法在历史上一直面临的挑战领域,并构建归因图来可视化模型行为。 AI
影响 引入了一种理解模型内部工作原理的新方法,有望提高LLM的可解释性和可信度。
排序理由 该集群描述了一篇详细介绍一种新颖的语言模型参数解释方法的论文。
AI 生成摘要 · Google Gemini · 来自 2 个来源。 我们如何撰写摘要 →